Multiscale Conditional Relationship Graph Network for Referring Relationships in Images
Jian Zhu and Hanli Wang
Overview:
Images contain not only individual entities, but also abundant visual relationships between entities. Conditioned on visual relationship triples < subject − relationship − object >, entities (subjects or objects) can be localized in images without ambiguity. However, it is challenging to efficiently model visual relationships since a specific relationship usually has dramatic intra-class visual differences when involved with different entities, quite a number of which are in small scale. In addition, the subject and the object in a relationship triple may have different best scales, and matching the subject and the object with different appropriate scales may improve prediction. To address these issues, a multi-scale conditional relationship graph network (MCRGN) is proposed to localize entities based on visual relationships. MCRGN is composed of an attention pyramid network to generate multi-scale attention maps and a conditional relationship graph network to aggregate and refine attention features to localize entities via passing vision-agnostic relationship contexts between entity attention maps. The experiments demonstrate the superiority of the proposed method compared with the previous powerful frameworks on three challenging benchmark datasets including CLEVR, Visual Genome and VRD.
Method:
An overview of the proposed MCRGN framework is shown in Fig. 1. Firstly, an attention pyramid network (APN) is designed for referring visual relationships to obtain multi-scale attention maps of the subject and the object. The large-scale attention maps with smaller receptive fields are more capable of modeling smaller entities, while the small-scale attention maps with larger receptive fields tend to capture larger entities. In addition, to deal with the subjectand the object in a relationship triple possessing different sizes, a conditional relationship graph network (CRGN) is further proposed for integrating the multi-scale attention maps for the subject and the object, which aggregates the attention features via modeling and passing the relationship contexts in the graph network. An attention map graph is first constructed, where each node denotes an attention map. Then, CRGN is applied to this attention map graph to aggregate and refine node features, where messages passed between nodes are conditioned on relationship triple features and learnt by convolutions. To mitigate the influence of the dramatic intra-class variance in relationships, vision-agnostic relationship features serve as conditional contexts in node features to restrict the refinement of visual features. After CRGN, the multi-scale attention maps for one entity jointly decide to generate the localization masks.
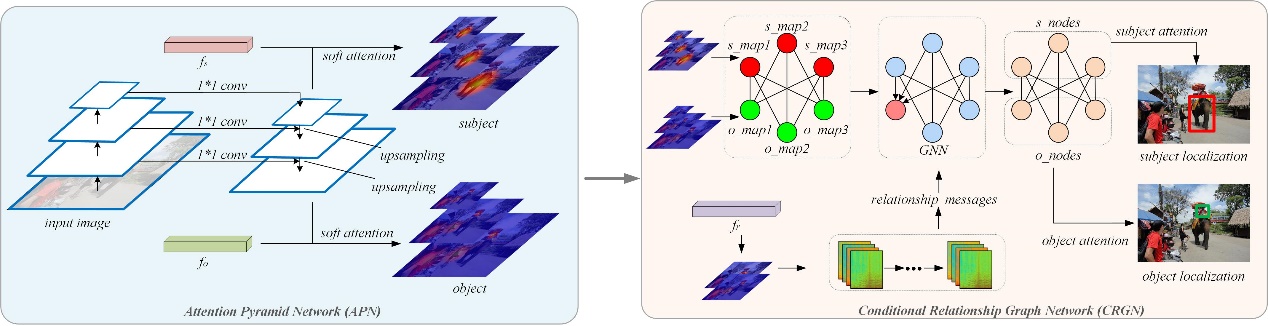
Fig. 1. An overall pipeline of the proposed MCRGN framework composed of an attention pyramid network to generate multi-scale attention maps and a conditional relationship graph network to aggregate and refine attention features to localize entities via passing vision-agnostic relationship contexts between entity attention maps.
Results:
The proposed MCRGN framework is evaluated on three visual relationship datasets, compared with several baseline methods. The mean intersection over union (IoU) is adopted to evaluate the model performance, which is a widely-used metric in localizing salient parts of an image. The mean IoU for the subject and the object on the three datasets are shown in Table 1. To verify the capacity of handling entities with small sizes of the proposed model, the mean IoU improvement results of twelve small entity categories on the Visual Genome dataset achieved by the proposed MCRGN against SSAS are shown in Table 2. The mean IoU improvement results of 25 relationship categories involved in the most entity categories on the Visual Genome dataset achieved by the proposed MCRGN against SSAS are reported in Table 3. In addition, several instances of successful cases and failure cases obtained by the proposed MCRGN for the task of referring relationships are shown in Fig. 2.
Table 1. Comparison of mean IoU for the subject and the object on the CLEVR, Visual Genome and VRD datasets in referring visual relationships task
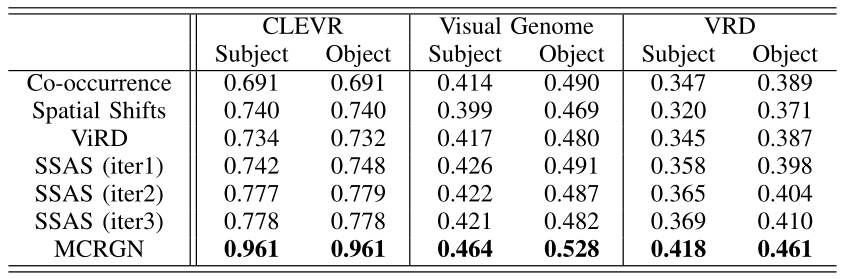
Table 2. The mean IoU improvement results of 12 entity categories with small sizes achieved by the proposed MCRGN against SSAS on the Visual Genome dataset.
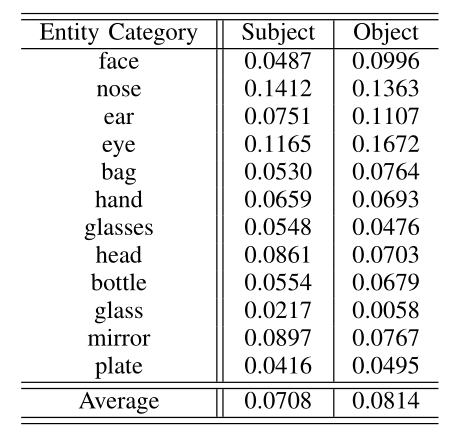
Table 3. The mean IoU improvement results of 25 relationship categories involved in the most entity categories achieved by the proposed MCRGN against SSAS on the Visual Genome dataset.

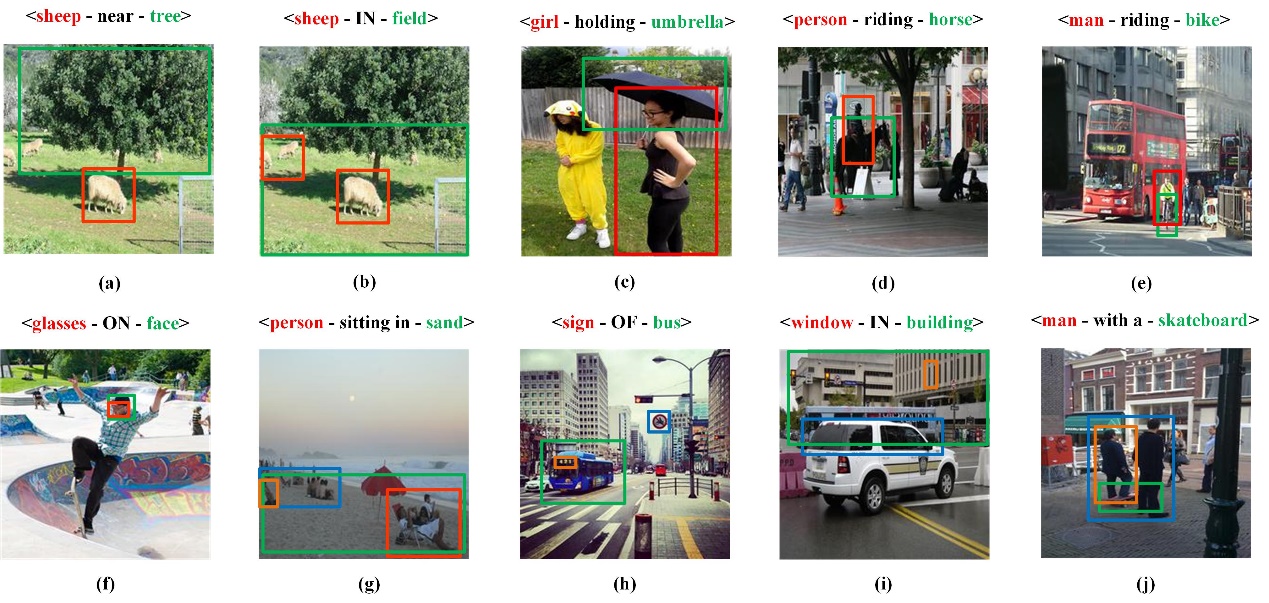
Fig. 2. Instances of successful cases and failure cases obtained by the proposed MCRGN for the task of referring relationships. (a)-(f) show the successful cases while (g)-(j) present the failure cases predicted by MCRGN. The red box and the green box represent the subject and the object localized, respectively. The orange box indicates the ground truth of missing entity and the blue box indicates wrong prediction.
Source Code:
Citation:
Please cite the following paper if you find this work useful:
Jian Zhu and Hanli Wang, Multiscale Conditional Relationship Graph Network for Referring Relationships in Images, IEEE Transactions on Cognitive and Developmental Systems, vol. 14, no. 2, pp. 752-760, Jun. 2022.