Multi-modal Learning for Affective Content Analysis in Movies
Yun Yi , Hanli Wang
Overview:
Affective content analysis is an important research topic in video content analysis, and has extensive applications in many fields. However, it is a challenging task to design a computational model for predicting emotions induced by videos, since the elicited emotions can be considered relatively subjective. Intuitively, several features of different modalities can depict the elicited emotions, but the correlation and influence of these features are still not well studied. To address this issue, we propose a multi-modal learning framework, which classifies affective contents in the valence-arousal space. Experimental results demonstrate that the proposed framework obtains the state-of-the-art results on two challenging datasets of video affective content analysis.
Method:
A multi-modal learning framework is proposed to classifie videos in the valence-arousal space. In this framework, we select three features to depict affective contents in movies. In particular, we employ the Motion Keypoint Trajectory (MKT) feature to describe the affective content, utilize the feature vectors extracted by Temporal Segment Networks (TSN) to depict motion and scene cues, and use a global audio feature extracted by the openSMILE toolkit to describe audio information. After the extraction of these feature vectors, the Fisher Vector (FV) model is used to encode the local features separately, and a scheme is designed to encode the vectors extracted by TSN. Then, an early fusion strategy is used to combine the vectors of these three features, and the linear Support Vector Machine (SVM) and Support Vector Regression (SVR) are employed to analyze the induced emotions.An overview of the proposed system is shown in Fig. 1.
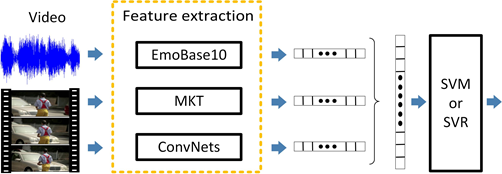
Fig. 1 An overview of the proposed affective content analysis framework.
Result:
Experiments are conducted on the datasets of the MediaEval 2015 Affective Impact of Movies Task (AIMT15) and the MediaEval 2016 Emotional Impact of Movies Task. AIMT15 is an extension of the LIRIS-ACCEDE dataset, and includes 10,900 short video clips extracted from 199 movies. Figure 2 shows some frames from the dataset. EIMT16 includes 11,000 short video clips extracted from movies. The official evaluation metric of AIMT15 is the global accuracy. Mean Squared Error (MSE) and Pearson Correlation Coefficient (PCC) are the standard evaluation metrics of EIMT16.

Fig. 2 Example frames from AIMT15.
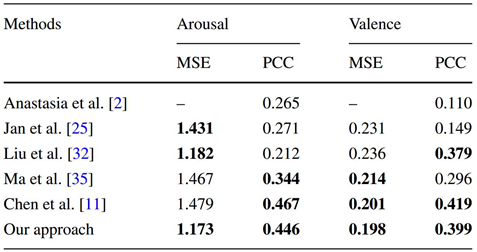
The proposed framework combines three features (i.e., ConvNets, MKT and EmoBase10) by using the early fusion strategy. The results are separately evaluated on the two domains (i.e., arousal and valence) with the standard evaluation metrics (i.e., ACC on AIMT15, MSE and PCC on EIMT16). The comparison with other state-of-the-art methods on the two datasets are shown in Table 1 and Table 2, where "-" indicates that no available results are reported by the cited publications.
Table 1 Comparison with the state-of-the-art results on AIMT15.
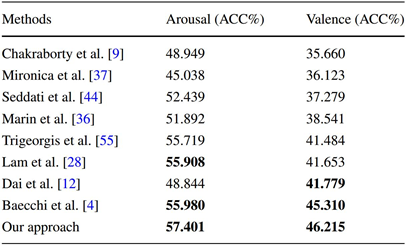
Table 2 Comparison with the state-of-the-art results on EIMT16.
Source Code:
MML_V1.0: ![]() MML_V1.0.zip
MML_V1.0.zip
Citation:
Please cite the following papers if you use this code.
Yun Yi and Hanli Wang, Multi-modal Learning for Affective Content Analysis in Movies, Multimedia Tools and Applications, 2018, in press, DOI: 10.1007/s11042-018-5662-9.