A Collaborative Scheduling-Based Parallel Solution for HEVC Encoding on Multicore Platforms
Hanli Wang, Bo Xiao, Jun Wu, Sam Kwong, and C.-C. Jay Kuo
Overview:
In order to meet the high computational demand to achieve superior coding efficiency and to explore the parallelism of parallel processing architectures, the emerging High Efficiency Video Coding (HEVC) standard has been designed to be more parallelizable than previous video coding standards. However, it is still desirable to design an efficient parallel HEVC encoder to fully exploit the parallelism of the increasingly powerful multicore platforms, especially when considering the amount of parallelism, the scalability of parallelization and the coding efficiency. In this work, a performance model of HEVC encoding is firstly introduced to investigate the speedup and the limitations of the technique of Wavefront Parallel Processing (WPP) under various conditions. Then, a Collaborative Scheduling-based Parallel Solution (CSPS) for HEVC encoding is proposed, which includes adaptive parallel mode decision, asynchronous frame level pixel interpolation and multi-grained task scheduling. The goal of the proposed CSPS aims to defeat the disadvantages of WPP and further improve the parallelization of HEVC encoding on multicore platforms.
Performance Model of WPP:
The WPP performance for HEVC encoding is influenced by various factors, including the amount of available computing resources, the size and content of video frames, the configured coding parameter sets and the implementation of WPP itself. Prior to implementing the proposed CSPS, it is desirable to develop a performance model for calculating the speedup of HM encoder when employing WPP under various conditions. However, it is never easy to deduce a general expression of speedup by means of analytical approaches for the common encoding situations. In this work, we build a performance model of WPP through simulation algorithms. The performance model helps to observe the shortages of the original WPP schema and guide the optimization of parallel encoding. The simulation algorithm is illustrated in Fig. 1 and the corresponding pseudo code is given below.

Fig. 1 Illustration of the simulation algorithm of the WPP performance.
CSPS Implementation:
The proposed collaborative scheduling-based parallel framework is an integrated solution for HEVC encoding, which includes three components, namely an Adaptive Parallel Mode Decision (APMD) algorithm, an Asynchronous Frame-level Interpolation Filter (AFIF) and a multi-grained task scheduling strategy. The proposed APMD is developed not only to overcome the limitation of WPP in terms of the amount of parallelism but also to improve the coding efficiency as much as possible by making full use of the horsepower of the multicore platforms. Essentially, it dynamically creates multiple finer-grained parallel tasks for evaluating coding modes in the mode decision process of a CU so as to reduce the overall encoding time. Moreover, the APMD manages to cooperate with the existing early termination algorithm. To achieve the design goals, the proposed APMD utilizes the technique of recursive task allocation and adaptive task abortion engaged with the work-stealing algorithm for scheduling. An overview of the proposed APMD algorithm is illustrated in Fig. 2.
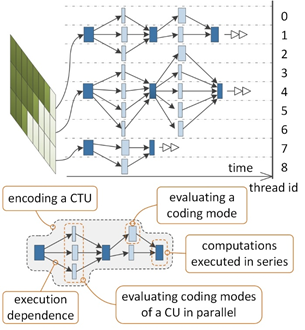
Fig. 2 Adaptive parallel mode decision.
Ramping inefficiency is caused by the inactive parts of the processing units during the ramp-up and ramp-down stages of WPP, and becomes much worse when the wavefront paradigm is applied iteratively for HEVC encoding. The proposed AFIF is designed to overcome ramping inefficiency by advancing workloads of fractional-pel interpolation filtering to the ramp-up stage of frame encoding. The mechanism of AFIF is illustrated in Fig. 3.
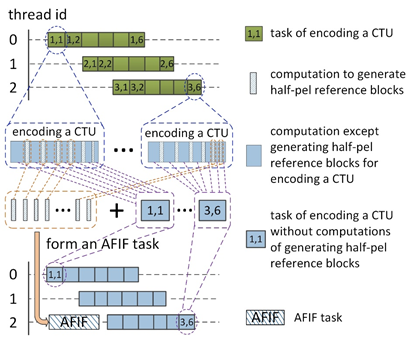
Fig. 3 Illustration of AFIF.
To reduce the overhead of scheduling and improve the parallel performance of CSPS, a multi-grained task scheduling strategy is proposed herein, which uses multiple independent schedulers to distribute tasks with different granularities. Each scheduler dispatches tasks onto a limited number of threads, which decreases the missing probability of task stealing and therefore improves the efficiency of task scheduling. The number of threads severed by the same scheduler is changed dynamically during encoding and is jointly determined by the amount of computing resources, the approximate number of parallel tasks to be spawned and the granularity of the tasks. The task scheduling strategy is illustrated in Fig. 4.
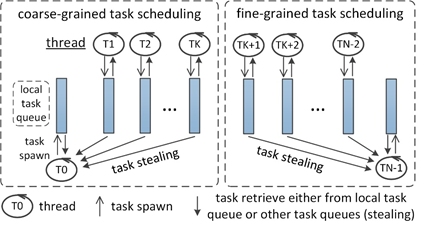
Fig. 4 Multi-grained task scheduling.
Experimental Results:
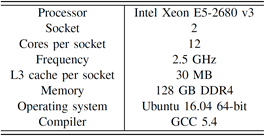
The detailed information of the platform for experiments is listed in Table I.
Table I Platform Configuration
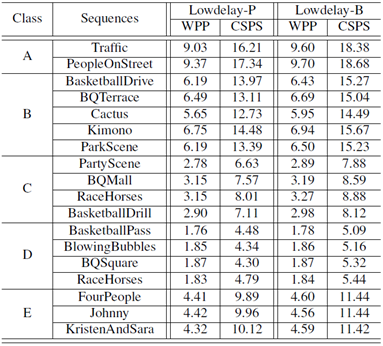
The average speedup performances achieved by WPP and the proposed CSPS over the anchor encoder for both the lowdelay-P and lowdelay-B configurations are tabulated in Table II.
Table II Average Speedup achieved by CSPS
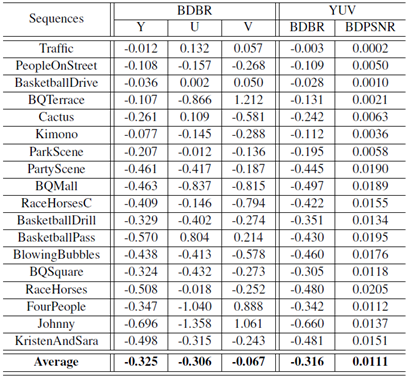
One of the most novel contributions of this work lies in the improvement of coding efficiency, whereas most of the previous works to parallelize HEVC encoding struggle to remain an acceptable coding loss. The coding efficiency of the proposed framework is compared with the anchor encoder in terms of Bjφntegaard Delta Bit Rate (BDBR, %) and Bjφntegaard Delta Peak Signal-to-Noise Ratio (BDPSNR, dB) using the above four Qp points of 22, 27, 32 and 37. The experimental results are tabulated in Table III and IV.
Table III Comparison of coding efficiency for lowdelay-P
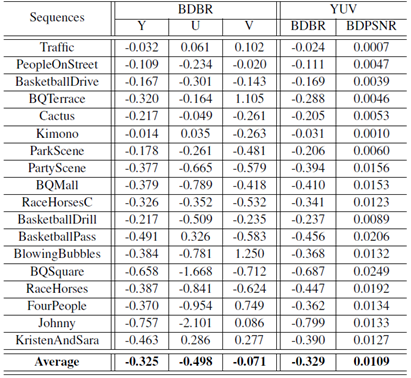
Table IV Comparison of coding efficiency for lowdelay-B
The parallel scalability of the proposed CSPS is analyzed in terms of the number of processor-cores that can be harnessed in the system. The experimental speedup under different number of processor-cores is plotted in Fig. 5.
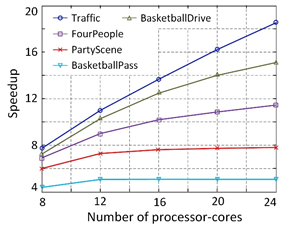
Fig. 5 Speedup achieved by CSPS with different number of processor-cores.
Download: [![]() pre-built-binaries.zip]
pre-built-binaries.zip]
Pre-built binaries of the proposed CSPS encoder on Windows and Ubuntu
1. Windows (Win7, Win8 and Win10)
2. Ubuntu (12.04, 14.04 and 16.04)
Instructions for Running CSPS Encoder:
Run the CSPS encoder:
1. Prepare the configuration files and video sequences;
2. Enter the root directory containing the CSPS encoder;
3. ./TAppEncoderStatic -c a-config-file.cfg -f 200 -q 24 -v -1 --WaveFrontSynchro=1 --EnableWPP=1 --ParallelMD=1 --FrameIF=1 --RampingOpt=1
Specific command arguments
All contributions proposed by CSCP, including WPP multithreading implementation, adaptive parallel mode decision and asynchronous frame-level interpolation filter, can be enabled through the command arguments as the original ones of HM do. For example, multithreading implementation of WPP can be enabled by providing argument like ‘--EnableWPP=1’
1) EnableWPP, WPP works jointly with flag WaveFrontSynchro.
2) ParallelMD, adaptive parallel mode decision.
3) FrameIF, frame-level interpolation filter.
RampingOpt, optimization for ramping inefficiency by using FrameIF.
Citation:
Please cite the following paper if this work helps your research.
Hanli Wang, Bo Xiao, Jun Wu, Sam Kwong, and C.-C. Jay Kuo, A Collaborative Scheduling-based Parallel Solution for HEVC Encoding on Multicore Platforms, IEEE Transactions on Multimedia, vol. 20, no. 11, pp. 2935-2948, Nov. 2018.