Structure-aware Generative Adversarial Network for Text-to-image Generation
Wenjie Chen, Zhangkai Ni, Hanli Wang
Overview:
Text-to-image generation aims at synthesizing photo-realistic images from textual descriptions. Existing methods typically align images with the corresponding texts in a joint semantic space. However, the presence of the modality gap in the joint semantic space leads to misalignment. Meanwhile, the limited receptive field of the convolutional neural network leads to structural distortions of generated images. In this work, a structure-aware generative adversarial network (SaGAN) is proposed for (1) semantically aligning multimodal features in the joint semantic space in a learnable manner; and (2) improving the structure and contour of generated images by the designed content-invariant negative samples. Compared with the state-of-the-art models, experimental results show that SaGAN achieves over 30.1% and 8.2% improvements in terms of FID on CUB and COCO datasets, respectively.
Method:
The pipeline of the proposed SaGAN for text-to-image generation is shown in Fig. 1. We adapt the unconditional StyleGAN to a conditional generative model by combining CLIP with StyleGAN. Firstly, a parameter-shared semantic perspective extraction (SPE) module is introduced to mitigate the modality gap. The semantic similarity between multimodal features is calculated from a specific perspective to improve the accuracy of semantic alignment. Secondly, a structure-aware negative data augmentation (SNDA) strategy is adopted to prompt the model to focus on the structure and contour of the image. A content-invariant geometric transformation is designed to obtain distorted images as an additional source of negative samples, which is consistent with the real image in content and style but distorted in structure and contour.
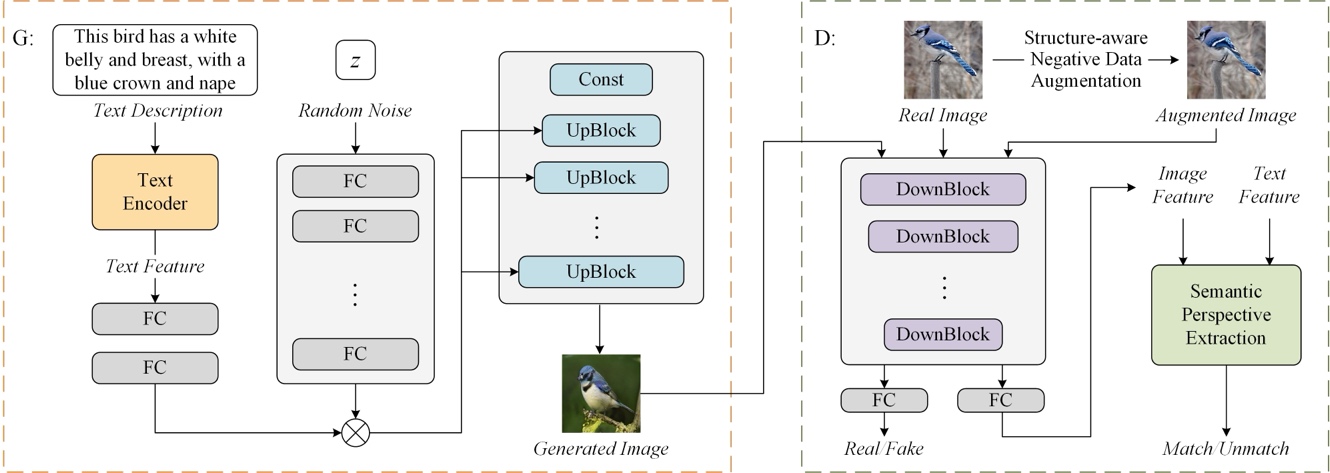
Fig. 1. Overview of the proposed SaGAN.
As shown in Fig. 2, the thin-plate-spline interpolation is utilized to reposition the pixels on the real image according to the movement from the source point to the destination point. By setting grid points, we can transform the image structure with different densities and scales. The augmented images which preserve the content and style of real images can force the network to focus on the structure and contour.

Fig. 2. The content-invariant geometric transformation.
Result:
We compare SaGAN with the state-of-the-art text-to-image methods. The comparison results are shown in Table 1. The remarkable performances on the datasets demonstrate the superiority of our SaGAN. We conduct extensive ablation experiments to verify the impact of the proposed SNDA and SPE on the proposed SaGAN, the experimental results are given in Table 2. In Table 3, we compare shared SPE and unshared SPE, where the latter refers to using two SPE modules for text and image features respectively. In Table 4, we compare our SNDA with other negative data augmentation strategies.
Table 1. Comparison with state-of-the-art methods on CUB and COCO datasets, the top-3 performances are highlighted in red, blue, and black bold, respectively.
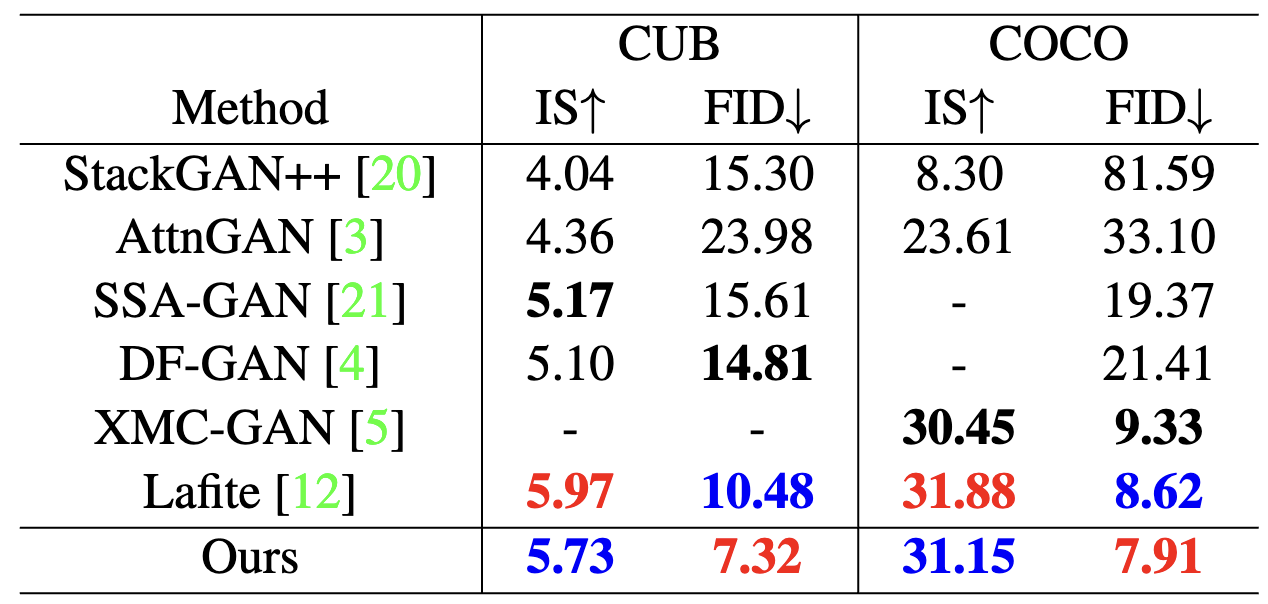
Table 2. Ablation study on CUB to investigate the effectiveness of our proposed modules.
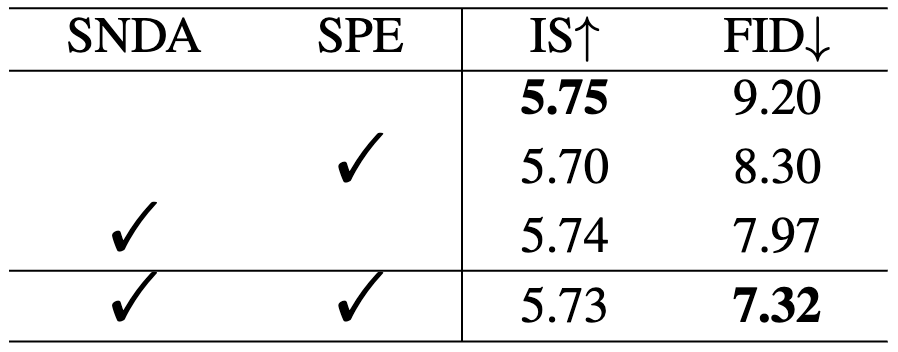
Table 3. Ablation study with different SPE settings on CUB.
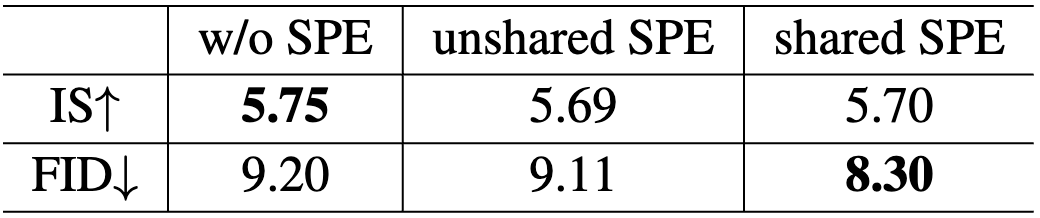
Table 4. Comparison with other negative data augmentation strategies on CUB.
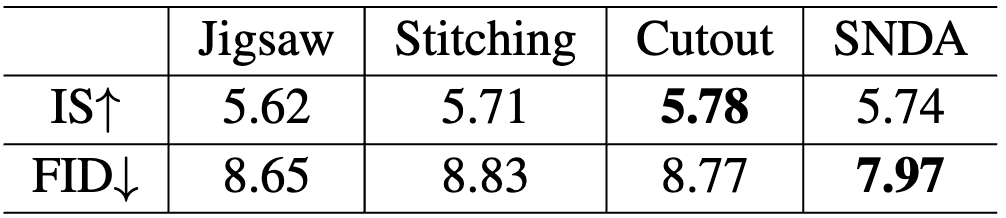
Figure 3 shows the qualitative comparisons between our SaGAN and Lafite, where images are generated conditioned on the description from the CUB dataset. A closer look at the image details reveals that the images generated by SaGAN have more vivid details.

Fig. 3. Qualitative comparison between SaGAN and Lafite.
Source Code:
Citation:
Please cite the following paper if you find this work useful:
Wenjie Chen, Zhangkai Ni, and Hanli Wang, Structure-aware Generative Adversarial Network for Text-to-image Generation, 2023 IEEE International Conference on Image Processing (ICIP'23), Kuala Lumpur, Malaysia, accepted, Oct. 8-11, 2023.