Adaptive Token Excitation With Negative Selection For Video-Text Retrieval
Juntao Yu, Zhangkai Ni, Taiyi Su, and Hanli Wang
Overview:
Video-text retrieval aims to efficiently retrieve videos from large collections based on the given text, whereas methods based on the large-scale pre-trained model have drawn sustained attention recently. However, existing methods neglect detailed information in video and text, thus failing to align cross-modal semantic features well and leading to performance bottlenecks. Meanwhile, the general training strategy often treats semantically similar pairs as negatives, which provides the model with incorrect supervision. To address these issues, an adaptive token excitation (ATE) model with negative selection is proposed to adaptively refine features encoded by a large-scale pre-trained model to obtain more informative features without introducing additional complexity. In detail, ATE is first advanced to adaptively aggregate and align different events described in text and video using multiple non-linear event blocks. Then a negative selection strategy is exploited to mitigate false negative effects, which stabilizes the training process. Extensive experiments on several datasets demonstrate the feasibility and superiority of the proposed ATE compared to other state-of-the-art methods.
Method:
As shown in Fig. 1, in order to efficiently obtain information-aligned video text features, the ATE model is designed, which consists of two components: token sequence extraction and adaptive token excitation. Specifically, the token sequence extraction module first encodes text and video by transformer and retains all text and video tokens, ensuring rich semantic information. Subsequently, the adaptive token excitation module refines the tokens by applying token sequence squeezing to reduce redundancy and token sequence reconstruction for adaptive alignment, which results in compact and semantically rich representations for text and video tokens. Furthermore, an additional negative selection strategy is used during training to identify and remove false negatives from the negative set. A dynamic threshold is utilized based on the confidence of the model, starting with a higher threshold and gradually lowering it during training which helps the model learn from more accurate supervision signals and achieve better performances.
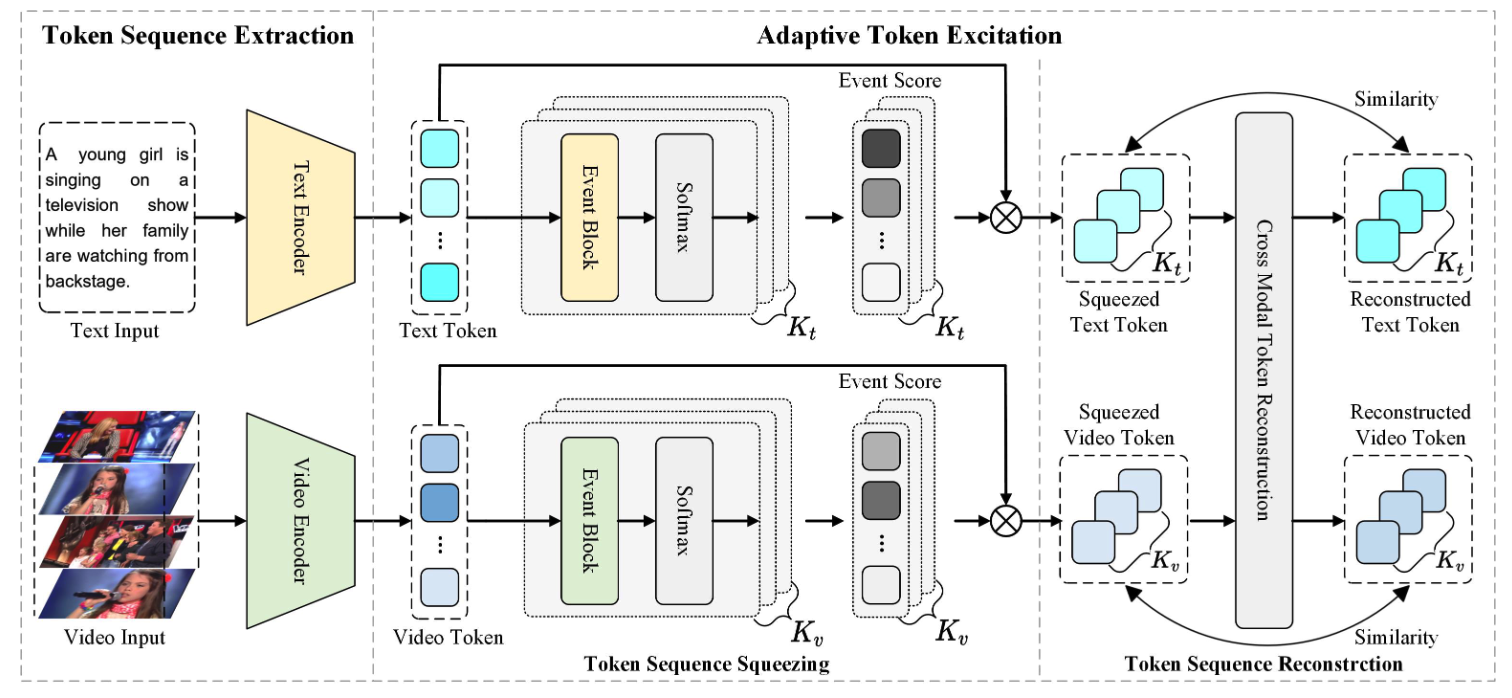
Fig. 1 Overview of the proposed ATE model for video-text retrieval, consisting of two components: token sequence extraction and adaptive token excitation.
Results:
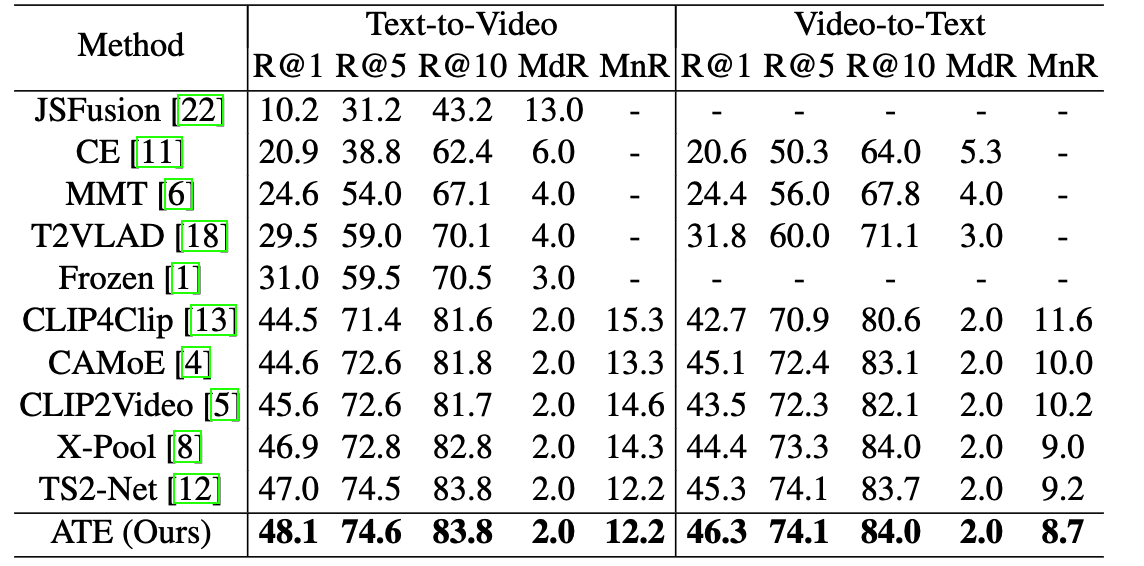
To comprehensively evaluate the performance of our proposed method on video text retrieval tasks, experiments are conducted on three benchmark datasets, including MSR-VTT, MSVD and LSMDC. The statistical results for MSR-VTT dataset are shown in Table 1.
Table 1 Comparison with the state-of-the-art methods on MSR-VTT.
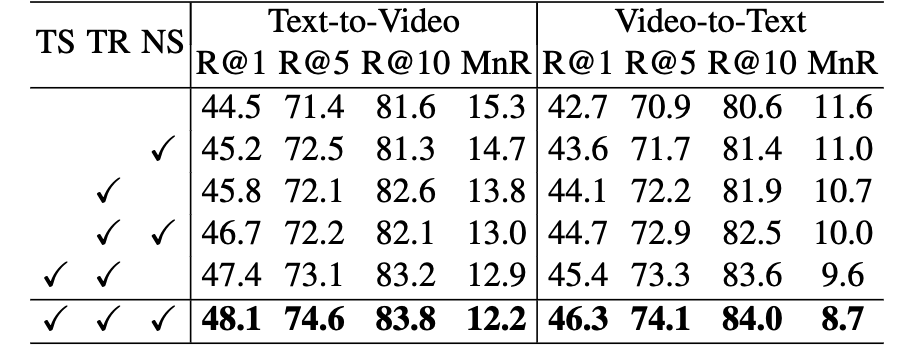
In Table 2, the importance of the token sequence squeezing (TS) module, the token sequence reconstruction (TR) module, and the negative selection (NS) strategy are evaluated respectively. It can be seen that each module yields considerable gains, while combining the three modules yields the best performance and significantly outperforms the baseline methods.
Table 2 Ablation studies on MSR-VTT to investigate the effectiveness of our proposed modules.
As depicted in Fig. 2, the similarity scores for the top 0.1% of negative samples and the mean similarity scores for positive samples are both approximately 0.3, corroborating the claim in previous work that the top 0.1% of negative samples indeed exhibit high similarity and should be considered as false negatives. Both empirical and theoretical evidence support that setting the threshold around 0.3 is a reasonable choice. By leveraging such an appropriate threshold, the model receives more accurate supervision signals, thereby achieving higher performances.
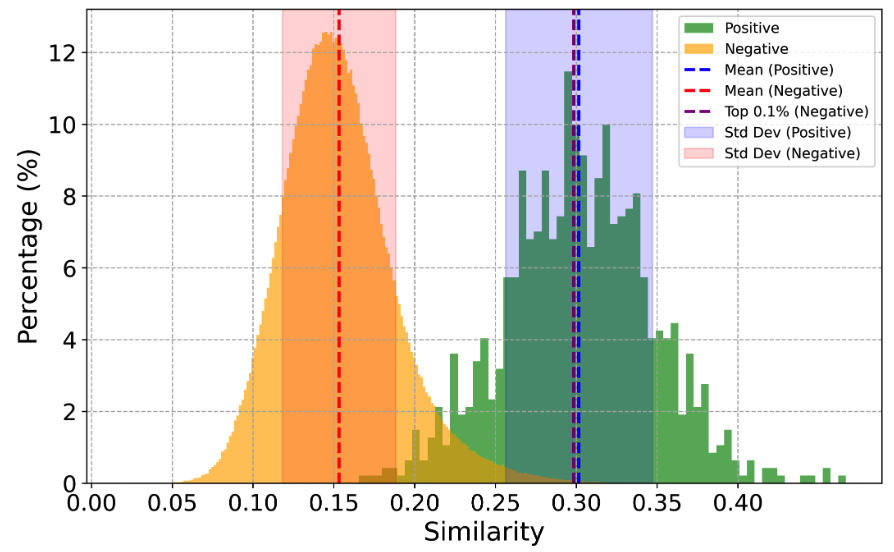
Fig. 2 Similarity distribution for positive sample pairs and negative sample pairs on the MSR-VTT test set.
Fig. 3 shows two examples of the videos retrieved by our model and baseline model, where the text queries consist of multiple events. In both two examples, ATE successfully retrieves the ground-truth videos, while the baseline model returns several videos that are relevant but imprecise to the text queries. The results demonstrate that our method is capable of effectively capturing and aligning multiple event cues.

Fig. 3 Text-video retrieval results on MSR-VTT.
Source Code:
Citation:
Please cite the following paper if you find this work useful:
Juntao Yu, Zhangkai Ni, Taiyi Su, and Hanli Wang, Adaptive Token Excitation with Negative Selection for Video-Text Retrieval, 32nd International Conference on Artificial Neural Networks (ICANN’23), accepted, Heraklion city, Crete, Greece, Sept. 26-29, 2023.