Transductive Learning with Prior Knowledge for Generalized Zero-shot Action Recognition
Taiyi Su, Hanli Wang, Qiuping Qi, Lei Wang, Bin He
Overview:
It is challenging to achieve generalized zero-shot action recognition. Different from the conventional zero-shot tasks which assume that the instances of the source classes are absent in the test set, the generalized zero-shot task studies the case that the test set contains both the source and the target classes. Due to the gap between visual feature and semantic embedding as well as the inherent bias of the learned classifier towards the source classes, the existing generalized zero-shot action recognition approaches are still far less effective than traditional zero-shot action recognition approaches. Facing these challenges, a novel transductive learning with prior knowledge (TLPK) model is proposed for generalized zero-shot action recognition. First, TLPK learns the prior knowledge which assists in bridging the gap between visual features and semantic embeddings, and preliminarily reduces the bias caused by the visual-semantic gap. Then, a transductive learning method that employs unlabeled target data is designed to overcome the bias problem in an effective manner. To achieve this, a target semantic-available approach and a target semantic-free approach are devised to utilize the target semantics in two different ways, where the target semantic-free approach exploits prior knowledge to produce well-performed semantic embeddings. By exploring the usage of the aforementioned prior-knowledge learning and transductive learning strategies, TLPK significantly bridges the visual-semantic gap and alleviates the bias between the source and the target classes. The experiments on the benchmark datasets of HMDB51 and UCF101 demonstrate the effectiveness of the proposed model compared to the state-of-the-art methods.
Method:
The pipeline of the proposed TLPK for generalized zero-shot action recognition is shown in Fig. 1. The framework is composed of three components: (1) a trainable visual encoder to extract visual features from the input video; (2) a visual-semantic bridging module to project the visual features into the semantic space; (3) a label prediction module which is initialized with the semantics of both the source and the target classes and generates the probabilities of all classes. The TSA and TSF approaches adopt the same aforementioned model architecture, but with the following different ways to initialize the normalized semantic vectors of the target classes: (1) regarding TSA, the normalized semantic vectors of both source and target classes are directly obtained by the word2vec representations of the ground-truth labels; (2) as for TSF, the unsupervised k-Means clustering algorithm is applied to classify the generated target-class embeddings into clusters, where the normalized semantic vectors of the target classes are estimated by the centers of the clusters.
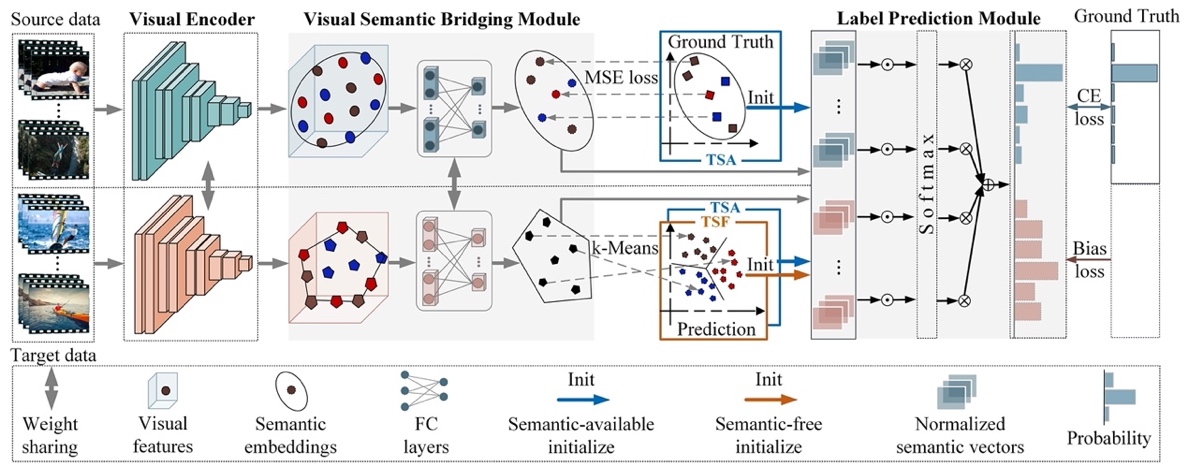
Fig. 1. Overview of the proposed TLPK framework.
Results:
The proposed model is compared with several state-of-the-art generalized zero-shot action recognition methods with the inductive setting and the transductive setting in Table 1. Here, “V” represents visual feature, “S” represents semantic embedding, “K” represents external knowledge, and “F/N” represents that the target semantics are free or not. In Table 2, the proposed model is also compared with existing state-of-the-art zero-shot action recognition methods in the conventional setting.
Table 1. Comparison between the proposed model and state-of-the-art generalized zero-shot action recognition methods in terms of average accuracy on HMDB51 and UCF101.
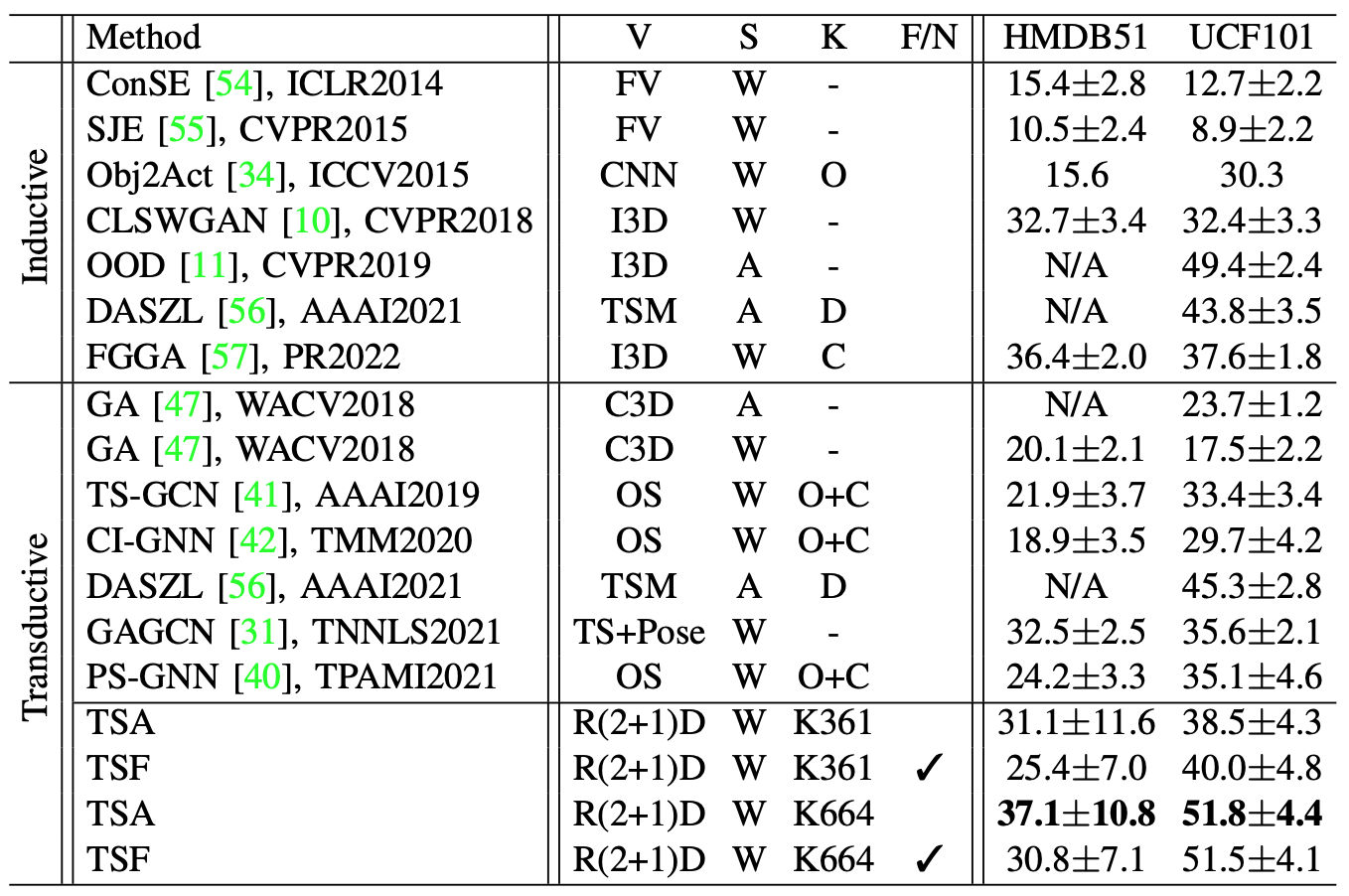
Table 2. Comparison between the proposed model and state-of-the-art conventional zero-shot action recognition methods in terms of average accuracy on HMDB51 and UCF101. ⋆: the resolution of the input frames are 224×224. TSA and TSF: the resolution of the input frames are 112×112.
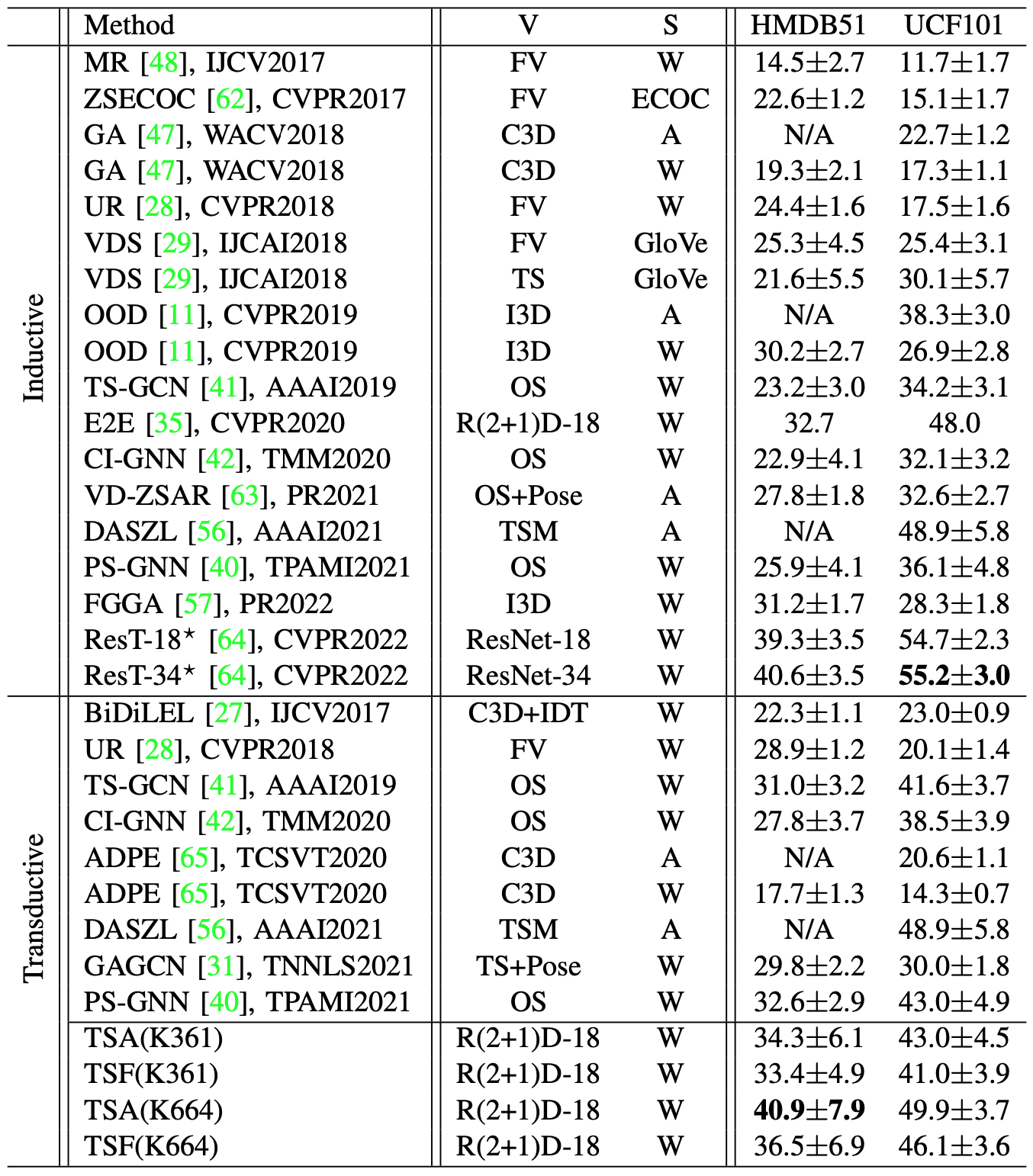
Fig. 2 shows a qualitative t-SNE illustration of the pre-trained model and the K664 model on UCF101, where the projected semantic embedding instances are shown as dots, the word2vec embeddings of the class names are shown as diamonds, and the embeddings from the same class are marked with the same color. Fig. 3 shows a qualitative t-SNE illustration of the PKL(K664) model and the TSA(K664) model at the training epochs 1-7 on UCF101. The source-class semantic embeddings are marked in blue, and the target-class semantic embeddings are marked in red.
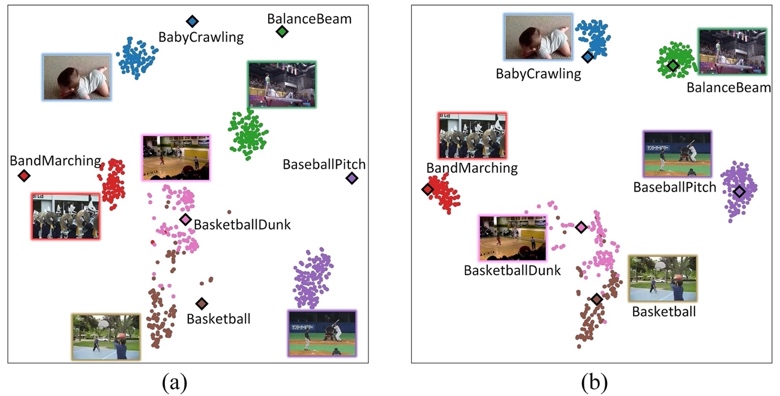
Fig. 2. Illustration of the distribution of semantic embeddings on 6 classes of UCF101. (a) Prior-knowledge learning is disabled. (b) Prior-knowledge learning is enabled.
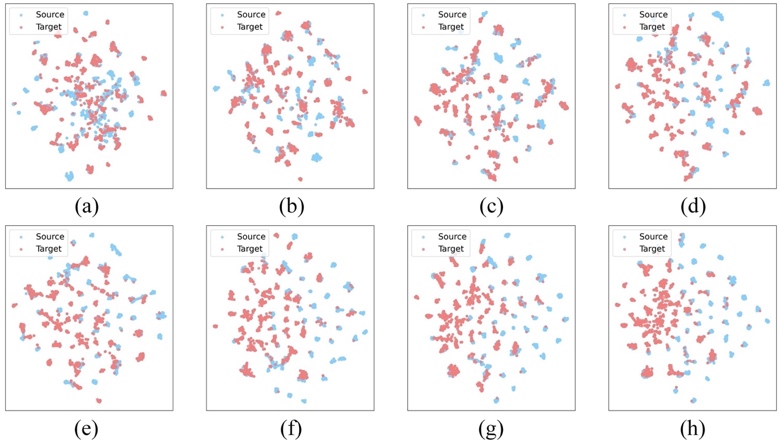
Fig. 3. Illustration of the distribution of semantic embeddings on UCF101. (a) The results of PKL(K664), which can be viewed as the training epoch 0. (b)-(h) The results of TSA(K664) at the training epochs 1-7.
Source Code:
Citation:
Please cite the following paper if you find this work useful:
Taiyi Su, Hanli Wang, Qiuping Qi, Lei Wang, and Bin He, Transductive Learning with Prior Knowledge for Generalized Zero-shot Action Recognition, IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 1, pp. 260-273, Jan. 2024.