Joint Graph Attention and Asymmetric Convolutional Neural Network for Deep Image Compression
Zhisen Tang, Hanli Wang, Xiaokai Yi, Yun Zhang, Sam Kwong and C.-C. Jay Kuo
Overview:
Recent deep image compression methods have achieved prominent progress by using nonlinear modeling and powerful representation capabilities of neural networks. However, most existing learning-based image compression approaches employ customized convolutional neural network (CNN) to utilize visual features by treating all pixels equally, neglecting the effect of local key features. Meanwhile, the convolutional filters in CNN usually express the local spatial relationship within the receptive field and seldom consider the long-range dependencies from distant locations. This results in the long-range dependencies of latent representations not being fully compressed. To address these issues, an end-to-end image compression method is proposed by integrating graph attention and asymmetric convolutional neural network (ACNN). Specifically, ACNN is used to strengthen the effect of local key features and reduce the cost of model training. Graph attention is introduced into image compression to address the bottleneck problem of CNN in modeling long-range dependencies. Meanwhile, regarding the limitation that existing attention mechanisms for image compression hardly share information, we propose a self-attention approach which allows information flow to achieve reasonable bit allocation. The proposed self-attention approach is in compliance with the perceptual characteristics of human visual system, as information can interact with each other via attention modules. Moreover, the proposed self-attention approach takes into account channel-level relationship and positional information to promote the compression effect of rich-texture regions. Experimental results demonstrate that the proposed method achieves state-of-the-art rate-distortion performances after being optimized by MS-SSIM compared to recent deep compression models on the benchmark datasets of Kodak and Tecnick.
Method:
As shown in Fig. 1, the proposed GAACNN is VAE structure based, with the asymmetric convolutions and the square-kernel convolutions filling the entire network in the form of combination. There are four ACNN modules in the encoder and the decoder, which can boost the effect of local key characteristics and speed up model training. Specifically, the ACNN modules are responsible for transforming the raw image into low-dimensional representations, following the rule of transform coding. Subsequently, self-attention is applied to focus on the rich-texture regions in the latent representations to improve compression efficiency. Similarly, there are two ACNN modules in the hyper-encoder and the hyper-decoder, and GAT is employed to exploit the long-range dependencies in the latent representations.
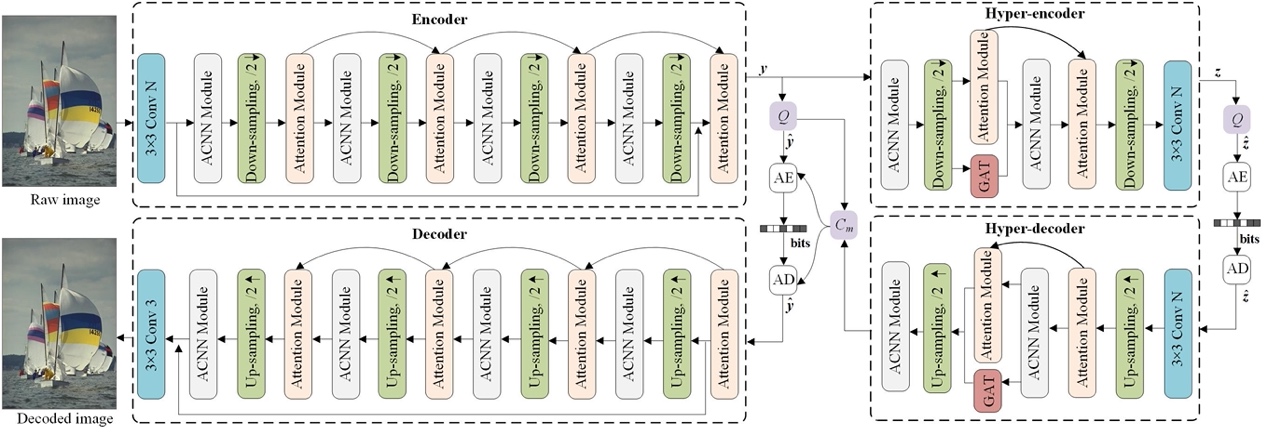
Fig. 1 Overview of the proposed GAACNN framework.
The structure of ACNN is shown in Fig. 2, the asymmetric block is composed of three convolutional layers and an activation function, i.e., Conv1, Conv2, Conv3 and ReLU. Conv1 and Conv3 are 1D asymmetric convolutions, which contain a convolution kernel of 3x1 and a convolution kernel of 1x3, respectively. Conv2 is a square convolution kernel of 3x3, which will be affected by Conv1 and Conv3 during residual learning to refine the extracted local key features and reinforce the expression ability of image compression network for local details.
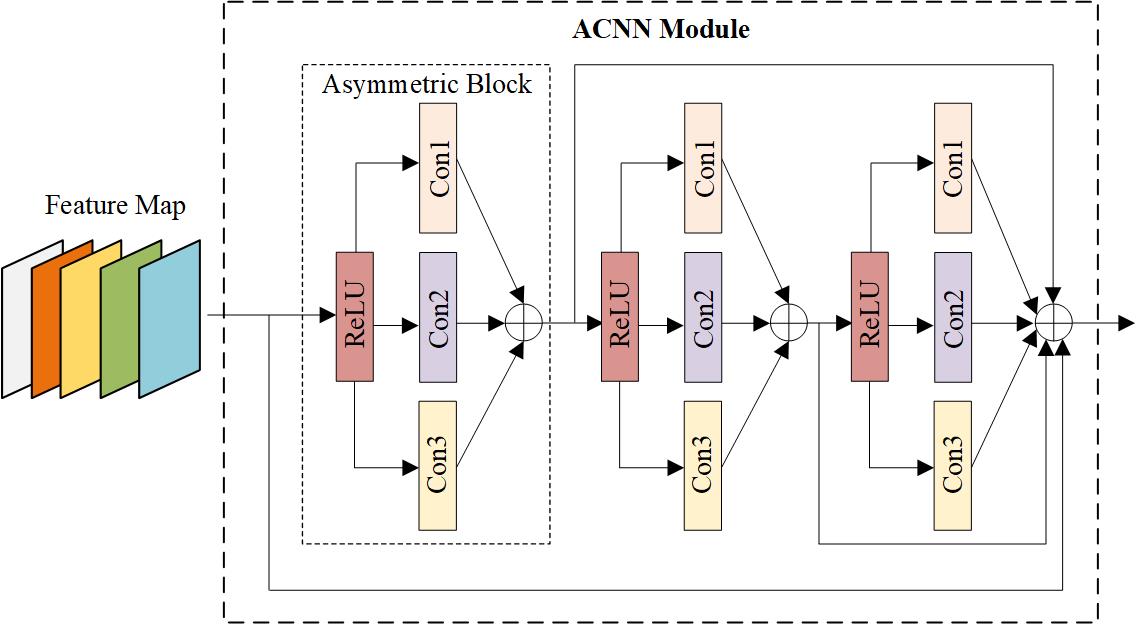
Fig. 2 Illustration of the ACNN architecture.
In addition, we flexibly combine the channel attention and the spatial attention by linearly weighting the channel-level relationship and the positional information. The channel and spatial attention mechanisms are shown in Fig. 3(a) and Fig. 3(b), respectively.
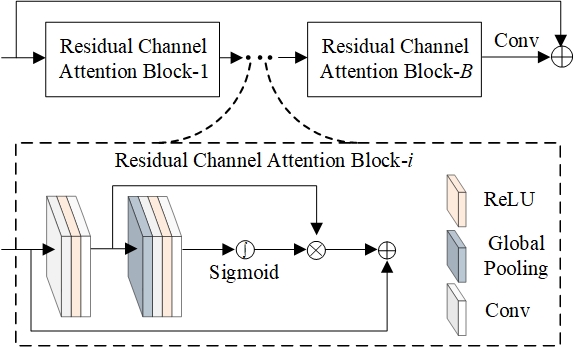
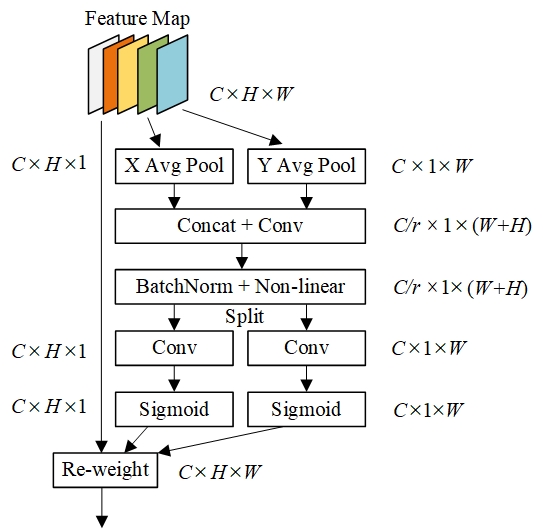
(a) Channel attention (b) Spatial attention
Fig. 3 The proposed attention module composed of channel attention and spatial attention mechanisms.
Results:
To evaluate the effectiveness of the proposed method, GAACNN is compared with four well-known image compression standards, including JPEG, JPEG2000, BPG as well as VTM, and recent deep image compression models, including the works of Chen et al., Hu et al., Li et al., Li et al., Lee et al., Minnen et al., Ball´e et al., Qian et al., Lu et al. and Jia et al. The rate-distortion performances of the competing approaches on the Kodak and Tecnick datasets are shown in Fig. 4 and Fig. 5, respectively.
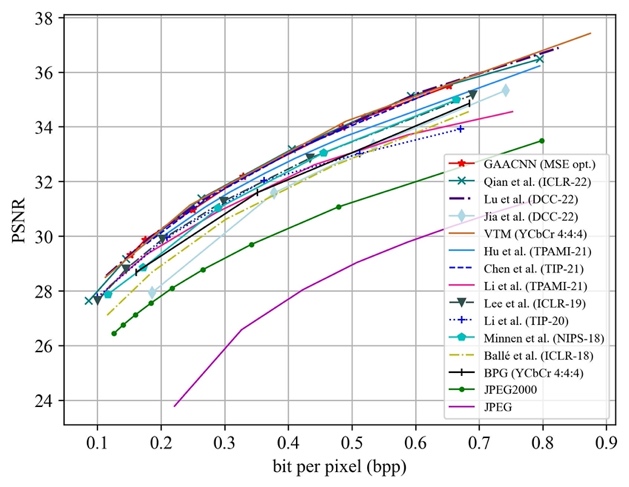
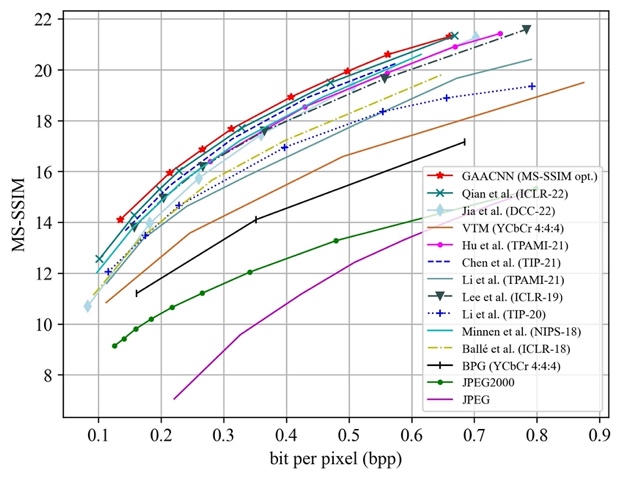
(a) Distortion measured by PSNR (b) Distortion measured by MS-SSIM
Fig. 4 Rate-distortion performance evaluation of image compression methods on the Kodak dataset.
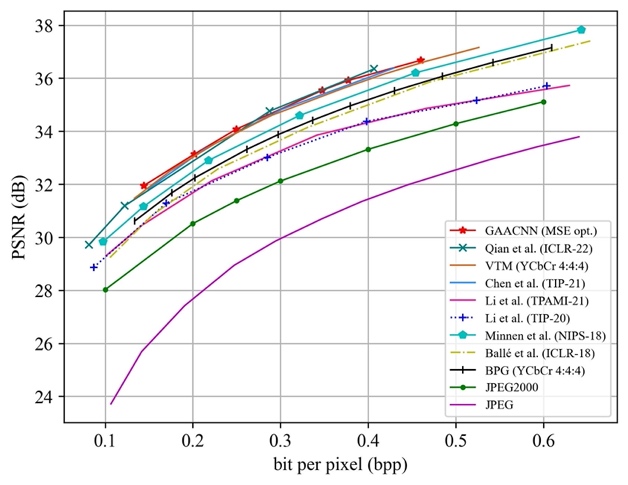
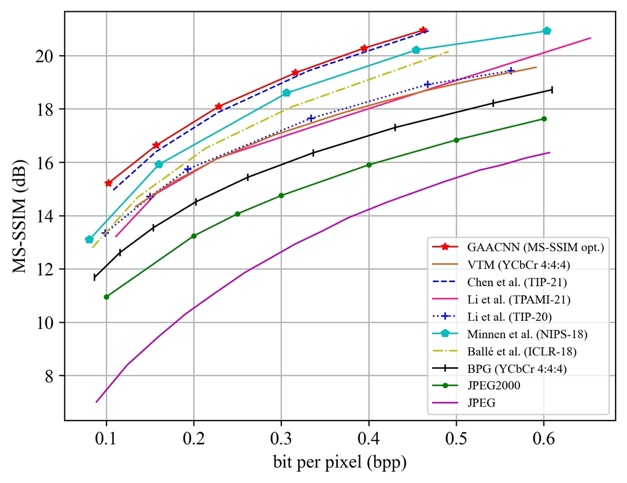
(a) Distortion measured by PSNR (b) Distortion measured by MS-SSIM
Fig. 5 Rate-distortion performance evaluation of image compression methods on the Tecnick dataset.
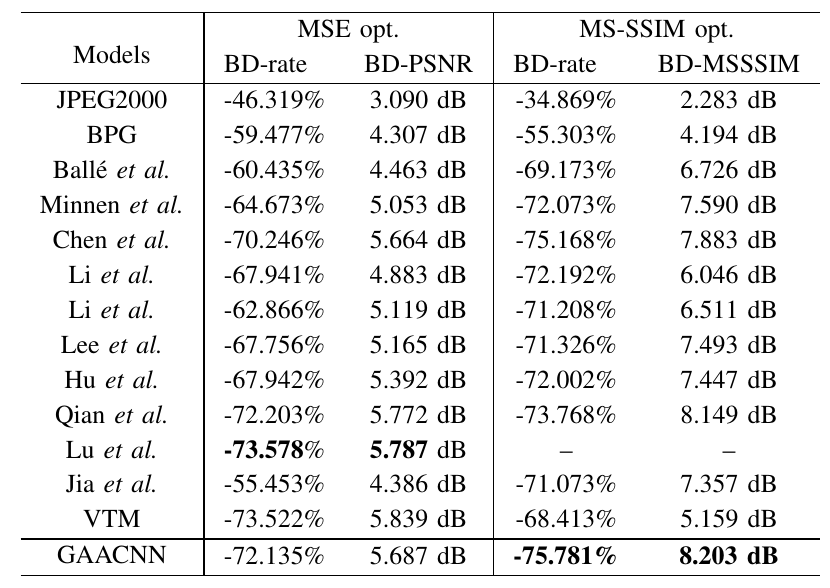
Moreover, Table I and Table II list the BD-rate, BDPSNR and BD-MSSSIM results of GAACNN and other competing compression schemes compared to the JPEG anchor on the Tecnick and Kodak datasets, respectively.
Table I BD-rate, BD-PSNR and BD-MSSSIM results of GAACNN and other competing compression schemes when compared with JPEG on the Tecnick dataset. The best result in each column is highlighted.
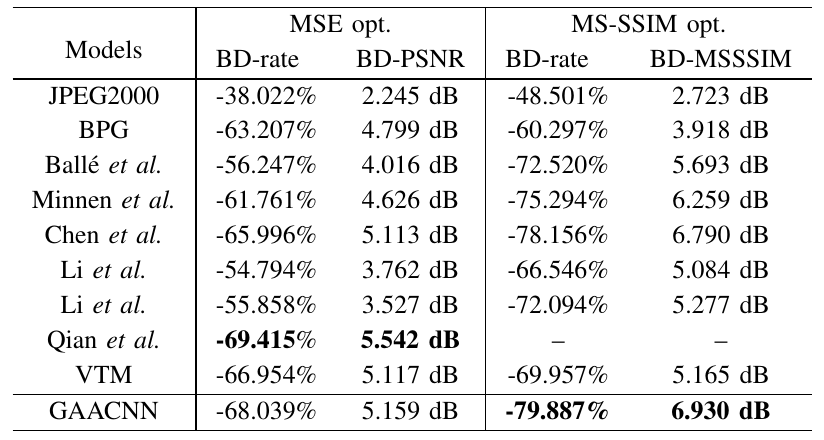
Table II BD-rate, BD-PSNR and BD-MSSSIM results of GAACNN and other competing compression schemes when compared with JPEG on the Kodak dataset. The best result in each column is highlighted.
Source Code:
Citation:
Please cite the following paper if you find this work useful:
Zhisen Tang, Hanli Wang, Xiaokai Yi, Yun Zhang, Sam Kwong and C.-C. Jay Kuo. Joint Graph Attention and Asymmetric Convolutional Neural Network for Deep Image Compression, IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 1, pp. 421-433, Jan. 2023.