Motion Keypoint Trajectory and Covariance Descriptor for Human Action Recognition
Yun Yi , Hanli Wang
Department of Computer Science and Technology, Tongji University, Shanghai, P. R. China
Overview:
Human action recognition from videos is a challenging task in computer vision. In recent years, histogram-based descriptors which are calculated along dense trajectories have shown promising results for human action recognition, but they usually ignore motion information of the tracking points and the relationship between different motion variables is not well utilized. To address this issue, we propose a Motion Keypoint Trajectory (MKT) approach and a Trajectory Based Covariance (TBC) descriptor which is calculated along the motion keypoint trajectories. The proposed MKT approach tracks motion keypoints at multiple spatial scales and employs an optical flow rectification algorithm to reduce the influence of camera motions, and thus achieves better performance than the Improved Dense Trajectory (IDT) approach well known in the literature. Especially, MKT is faster than IDT, because MKT does not need to use human detection and extracts fewer trajectories than IDT. Furthermore, the TBC descriptor outperforms the classical histogram-based descriptors, such as the Histogram of Oriented Gradient (HOG), Histogram of Optical Flow (HOF) and Motion Boundary Histogram (MBH). Experimental results on three challenging datasets (i.e., Olympic Sports, HMDB51 and UCF50) demonstrate that our approach is able to achieve better recognition performances than a number of state-of-the-art approaches.
Method:
In general, previous studies ignore the motion information of the tracking points and the relationship between different motion variables. To address these issues, we propose the Motion Keypoint Trajectory (MKT) and Trajectory Based Covariance (TBC) descriptor, which can be utilized as the basis of high-level algorithms for action recognition systems. After the extraction of local descriptors, the vectors of a video are separately encoded into a video-level signature vector by Fisher Vector (FV) model for each descriptor, then the linear Support Vector Machine (SVM) is utilized to classify actions. An overview of the proposed system is shown in Fig. 1.
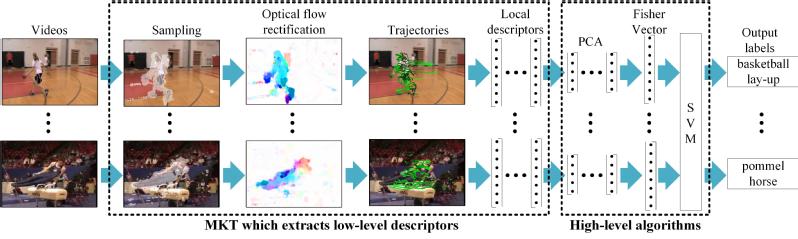
Fig. 1 An overview of the proposed system.
Result:
The MKT approach with Data Augmentation (DA) and Spatial-Temporal Pyramid (STP) is compared with other state-of-the-art approaches in Table 1, where “A+B” is the approach combining the techniques of A and B, and “-” indicates that no available results are reported by the cited publications.
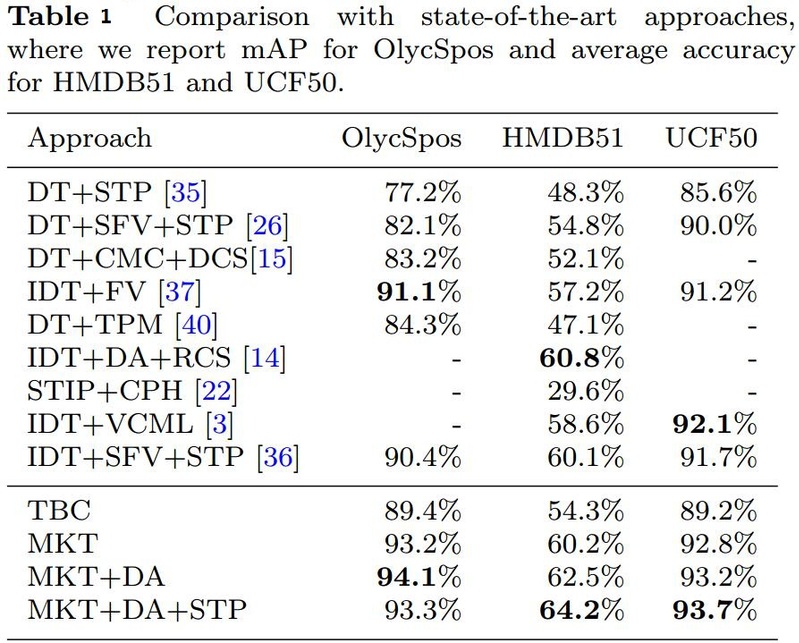
Figure 2 shows the confusion matrices for combined descriptors on HMDB51 and UCF50. The errors mainly occur between classes which are visually similar, like "sword exercise" and "draw sword" on HMDB51, "Swing" and "Tennis Swing" on UCF50.
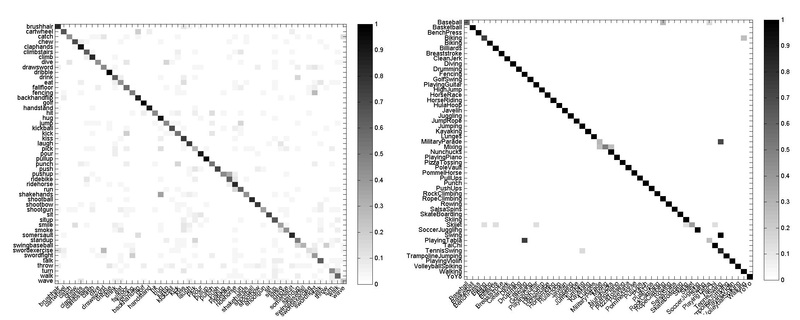
ig. 2 The confusion matrices for combined descriptors on HMDB51 (left) and UCF50 (right).
Source Code:
MKTBC-1.0: ![]() MKTBC_V1.0.zip
MKTBC_V1.0.zip
Citation:
Please cite the following paper when using our proposed MKT and TBC.
Yun Yi and Hanli Wang, Motion Keypoint Trajectory and Covariance Descriptor for Human Action Recognition, The Visual Computer, vol. 34, no. 3, pp. 391-403, 2018, DOI: 10.1007/s00371-016-1345-6.