Generative Planning with 3D-vision Language Pre-training for End-to-end Autonomous Driving
Tengpeng Li, Hanli Wang, Xianfei Li, Wenlong Liao, Tao He, Pai Peng
Overview:
Autonomous driving is a challenging task that requires perceiving and understanding the surrounding environment for safe trajectory planning. While existing vision-based end-to-end models have achieved promising results, these methods are still facing the challenges of vision understanding, decision reasoning and scene generalization. To solve these issues, a generative planning with 3D-vision language pre-training model named GPVL is proposed for end-to-end autonomous driving. The proposed paradigm has two significant aspects. On one hand, a 3D-vision language pre-training module is designed to bridge the gap between visual perception and linguistic understanding in the bird’s eye view. On the other hand, a cross-modal language model is introduced to generate holistic driving decisions and fine-grained trajectories with perception and navigation information in an auto-regressive manner. Experiments on the challenging nuScenes dataset demonstrate that the proposed scheme achieves excellent performances compared with state-of-the-art methods. Besides, the proposed GPVL presents strong generalization ability and real-time potential when handling high-level commands in various scenarios. It is believed that the effective, robust and efficient performance of GPVL is crucial for the practical application of future autonomous driving systems.
Method:
The overall pipeline of the proposed GPVL model is illustrated in Fig. 1. First, the backbone includes a 3D-vision encoder to obtain the basic BEV feature, then it is decoded into constrained detection, motion and map features. Second, the 3D-vision language pre-training module establishes the associations between vision and language features with the group-wise alignment. Finally, the cross-modal language model generates the future planning decision in an auto-regressive manner based on aligned visual feature and navigation prompt.
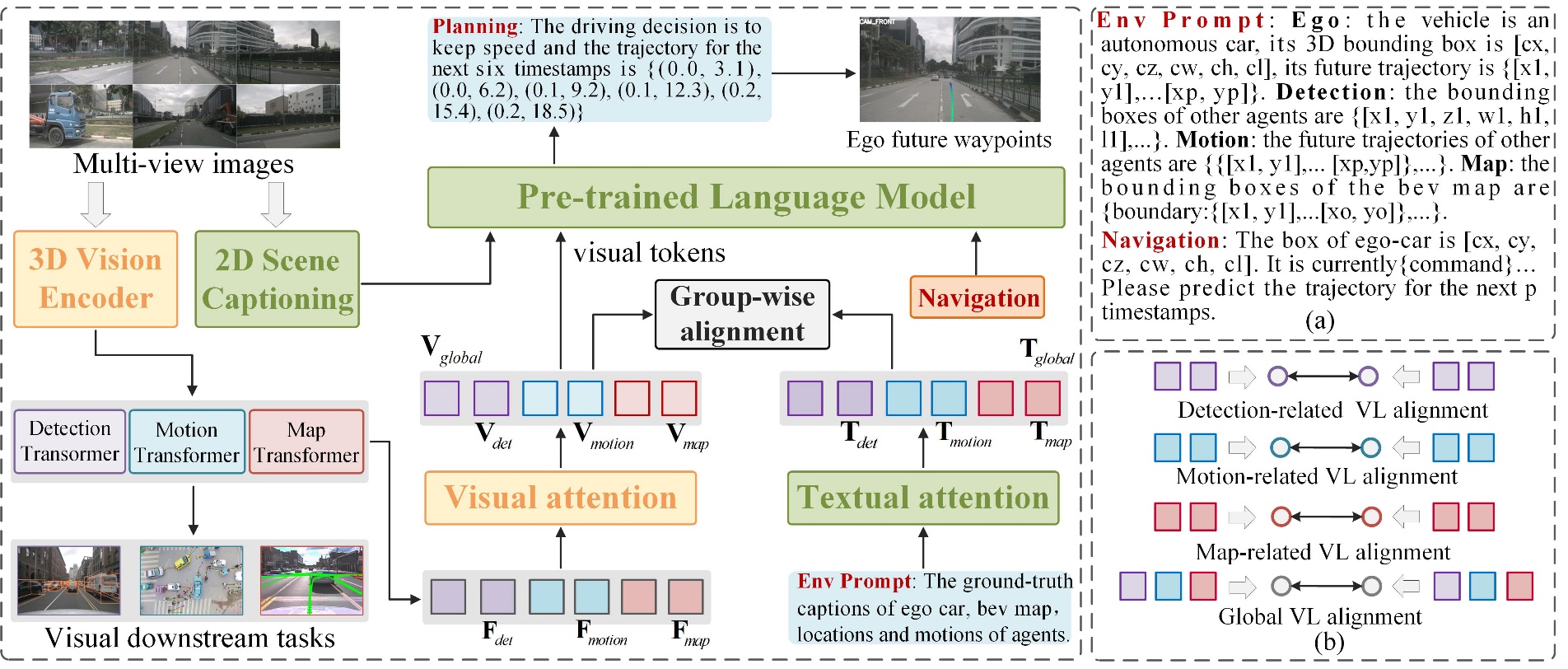
Fig. 1. Overview of the proposed GPVL framework.
Results:
The proposed GPVL is compared with several state-of-the-art autonomous drivingmodels on the nuScenes dataset. The experimental results are shown in Table 1, Table 2, Table 3 and Table 4. Then, qualitative experiments are conducted to verify the effectiveness of the proposed GPVL, as illustrated in Fig. 2.
Table 1. Open-loop planning performance. GPVL achieves the highest score on most evaluation metrics on the nuScenes val dataset. In open-loop evaluation, the ego status information of GPVL is deactivated for a fair comparison.
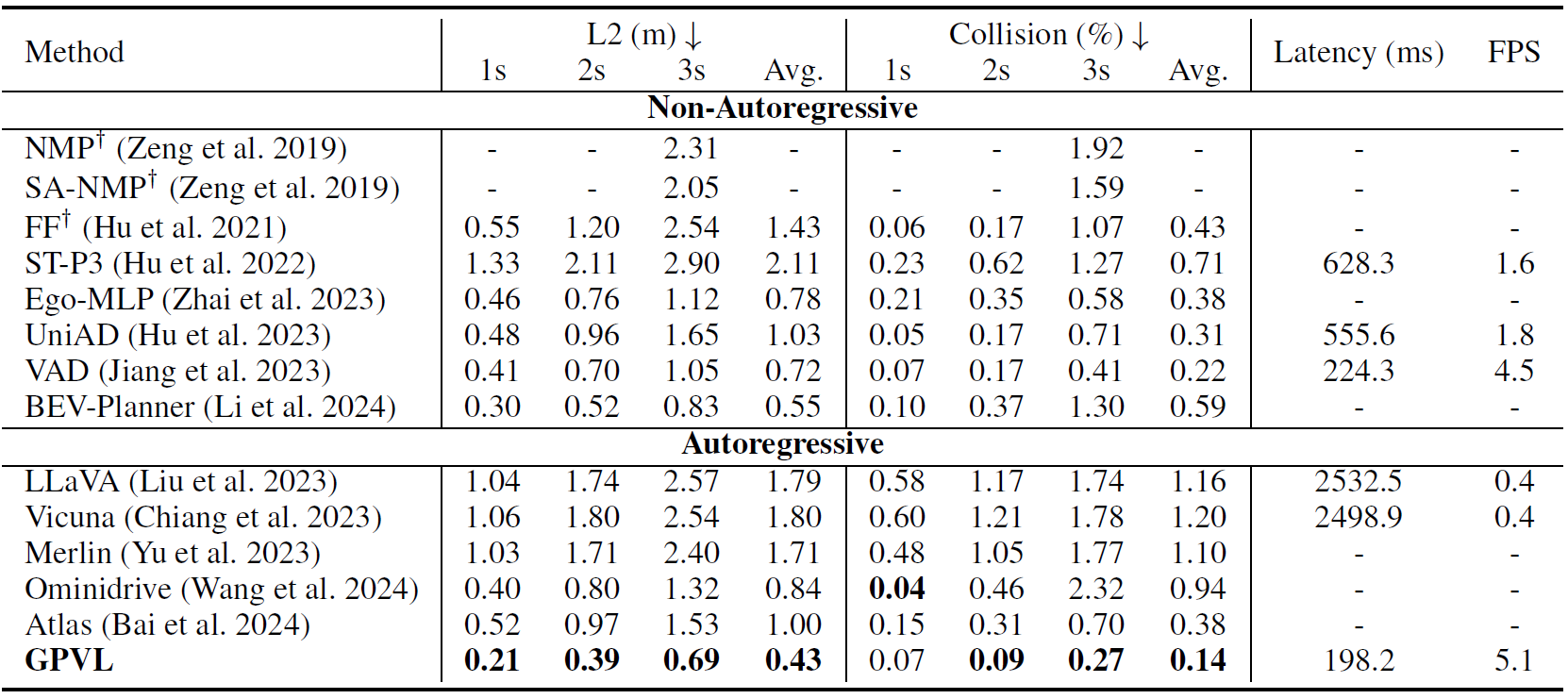
Table 2. Statistical results of L2 distance and collision rate with turn left, turn right and go straight commands.
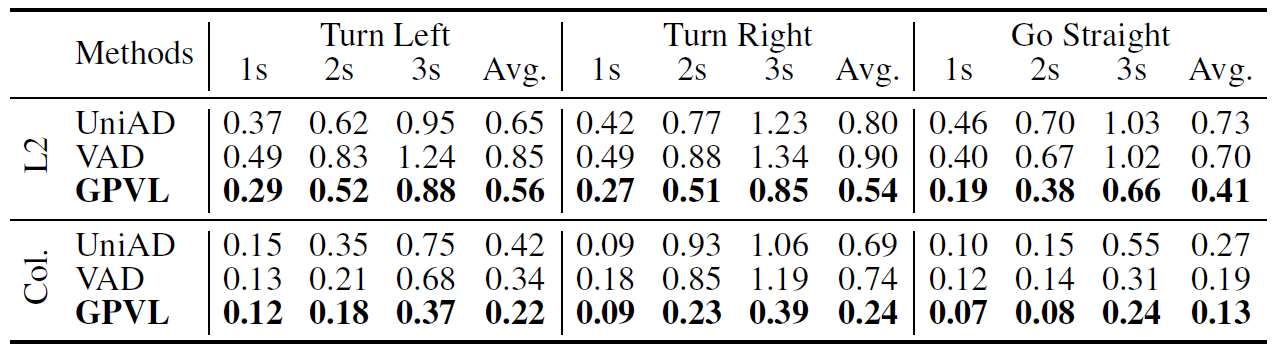
Table 3. Ablation study of GPVL on nuScenes, where Perc, Cap, VLP, GA and CLM represent perception modules, captioning model, 3D-vision language pre-training, group-wise alignment and cross-modal language model, respectively.
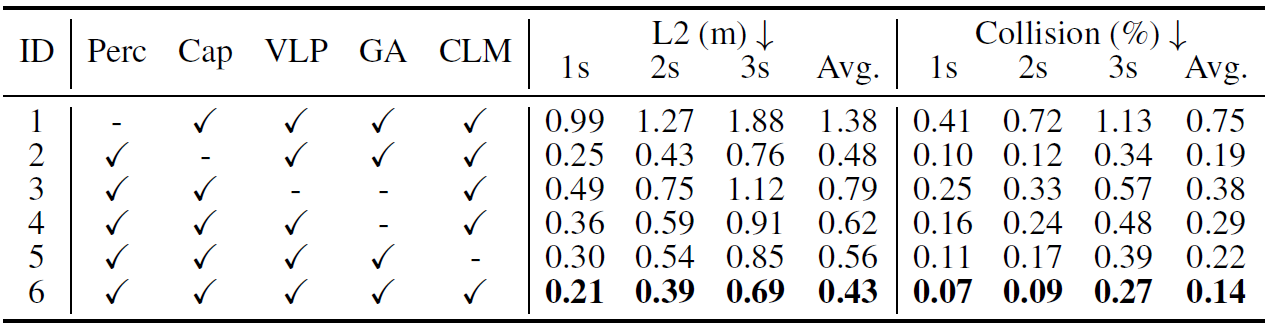
Table 4. Zero-shot performance on the new city, the models are trained on Boston and tested on Singapore in Group1, and the models are trained on Singapore and tested on Boston in Group2.
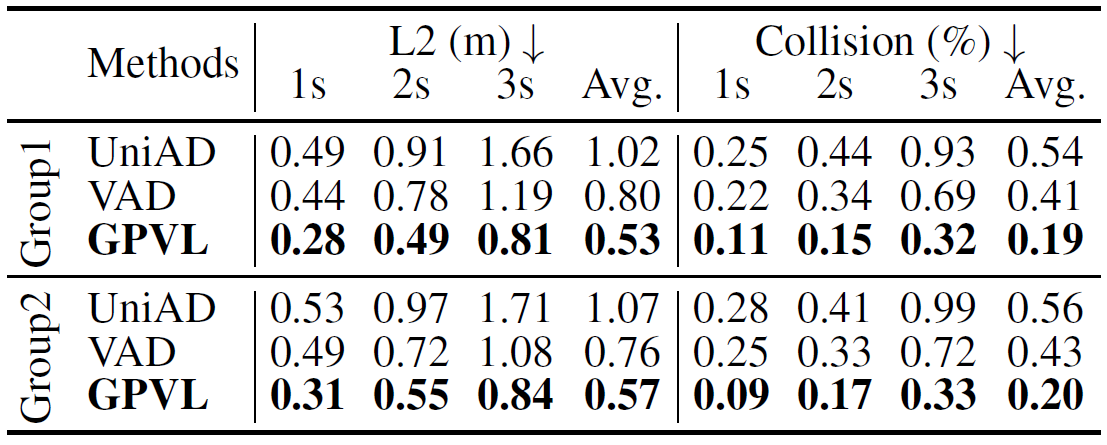
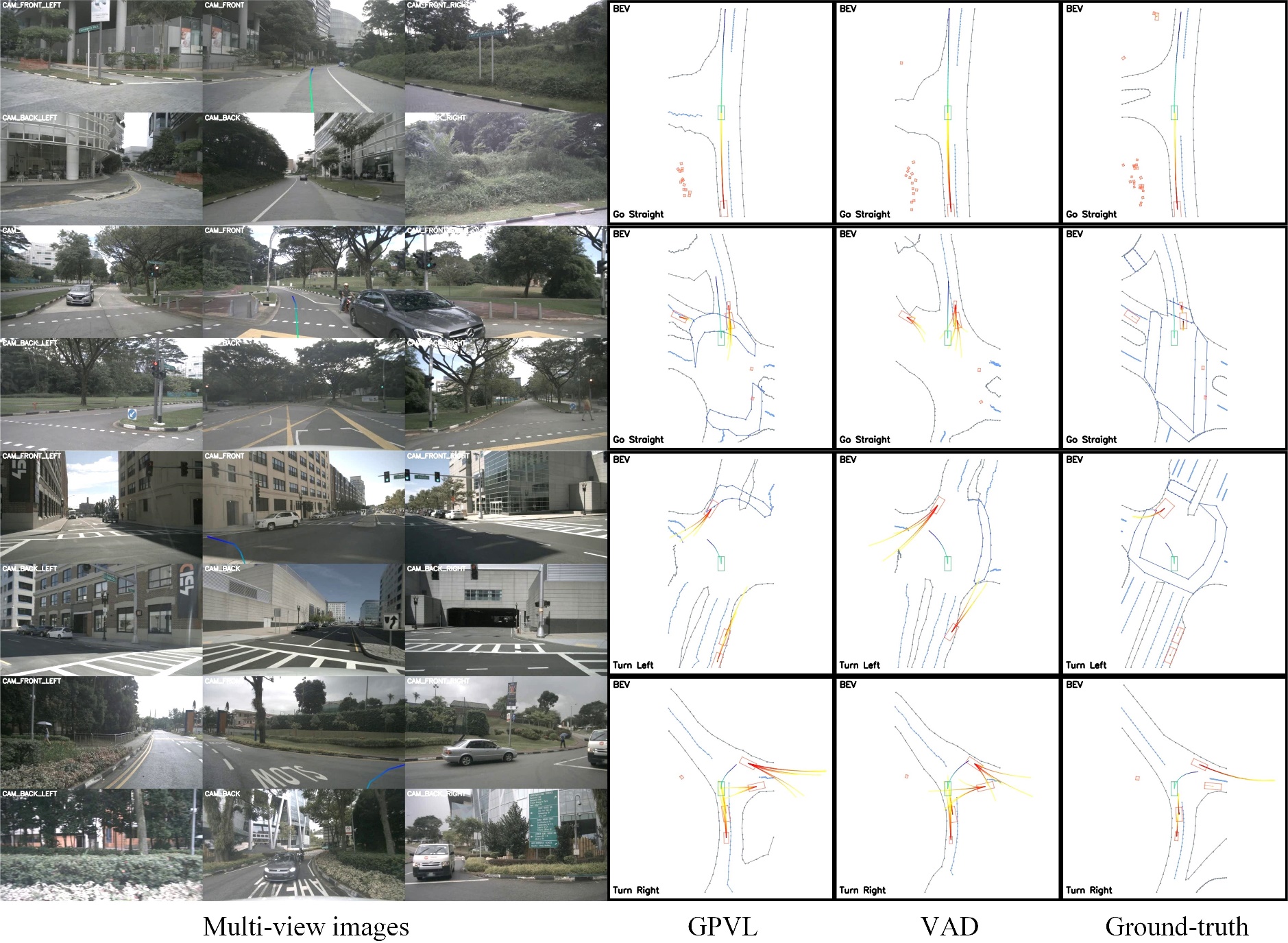
Fig. 2. Visualized comparison of the proposed GPVL, VAD and the ground-truth on the nuScenes dataset.
Source Code:
Citation:
Please cite the following paper if you find this work useful:
Tengpeng Li, Hanli Wang, Xianfei Li, Wenlong Liao, Tao He, Pai Peng, Generative Planning with 3D-vision Language Pre-training for End-to-end Autonomous Driving, The Thirty-Ninth AAAI Conference on Artificial Intelligence (AAAI'25), Philadelphia, Pennsylvania, USA, pp. 4950-4958, Feb. 25-Mar. 4, 2025.