Vision-Language Relational Transformer for Video-to-Text Generation
Tengpeng Li, Hanli Wang, Qinyu Li, Zhangkai Ni
Overview:
Video-to-text generation is a challenging task that involves translating video contents into accurate and expressive sentences. Existing methods often ignore the importance of establishing fine-grained semantics within visual representations and exploring textual knowledge implied by video contents, leading to difficulty in generating satisfactory sentences. To address these problems, a vision-language relational transformer (VLRT) model is proposed for video-to-text generation. Three key novel aspects are investigated. First, a visual relation modeling block is designed to obtain higher-order feature representations and establish semantic relationships between regional and global features. Second, a knowledge attention block is developed to explore hierarchical textual information and capture cross-modal dependencies. Third, a video-centric conversation system is constructed to complete multi-round dialogues by incorporating the proposed modules including visual relation modeling, knowledge attention and text generation. Extensive experiments on five benchmark datasets including MSVD, MSRVTT, ActivityNet, Charades and EMVPC demonstrate that the proposed scheme achieves remarkable performance compared with the state-of-the-art methods. Besides, the qualitative experiment reveals the system's favorable conversation capability and provides a valuable exemplar for future video understanding works.
Method:
The overall pipeline of the proposed VLRT model is illustrated in Fig. 1. First, the visual relation modeling block obtains higher-order characteristics of visual features and establishes semantic associations between regional and global features. Meanwhile, the knowledge attention block explores hierarchical textual information and captures cross-modal relationships. Finally, the text generation module produces video captions and completes multiple rounds of dialogues.
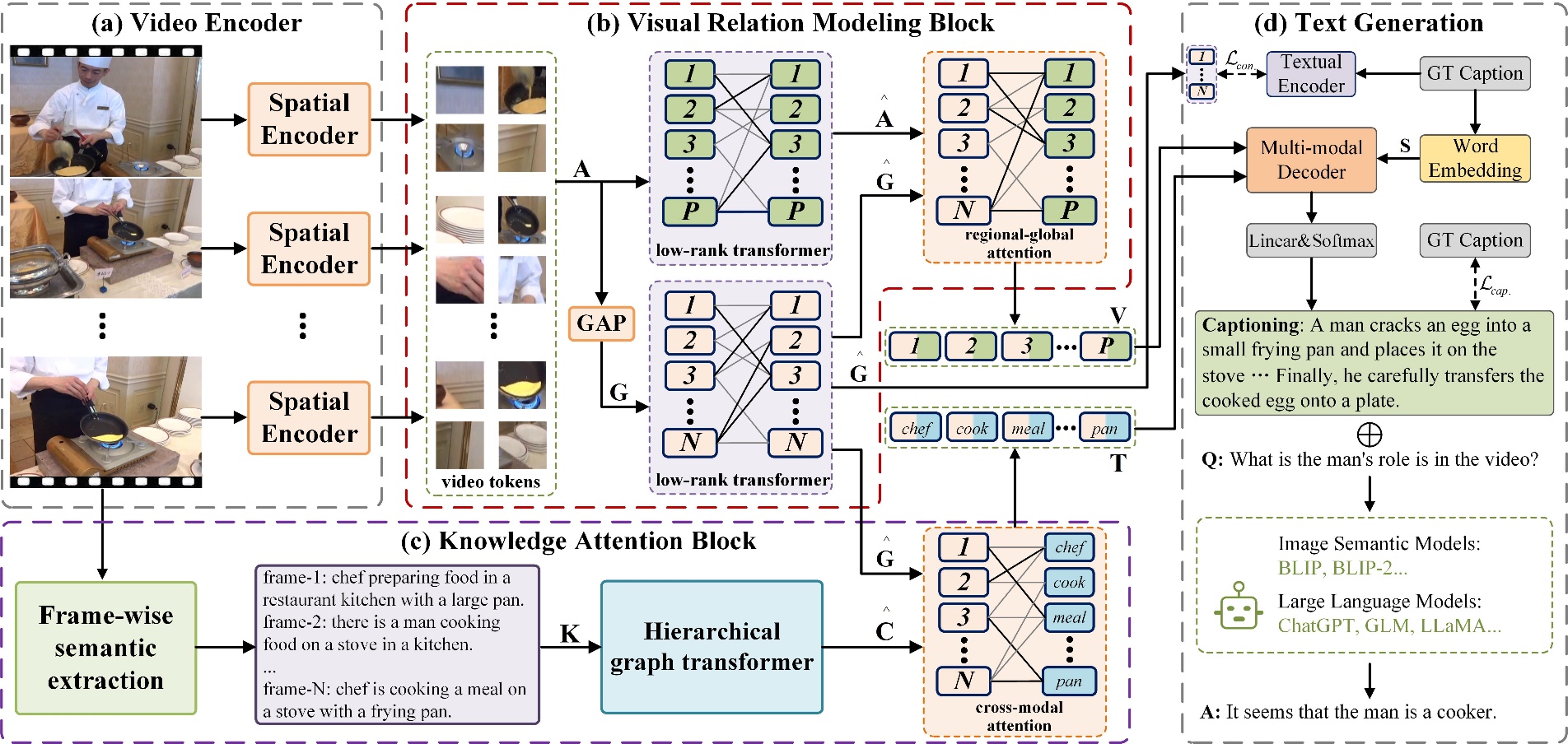
Fig. 1. Overview of the proposed VLRT framework.
Results:
The proposed VLRT is compared with several state-of-the-art video captioning models on five public datasets. The experimental results are shown in Table 1, Table 2 and Table 3. Then, qualitative experiments are conducted on three benchmark datasets to verify the effectiveness of the proposed VLRT, as illustrated in Fig. 2. Moreover, the visualization of video-centric conversation system is shown in Fig. 3 to demonstrate the capability of multi-round dialogues.
Table 1. Performance comparison on MSVD and MSRVTT.
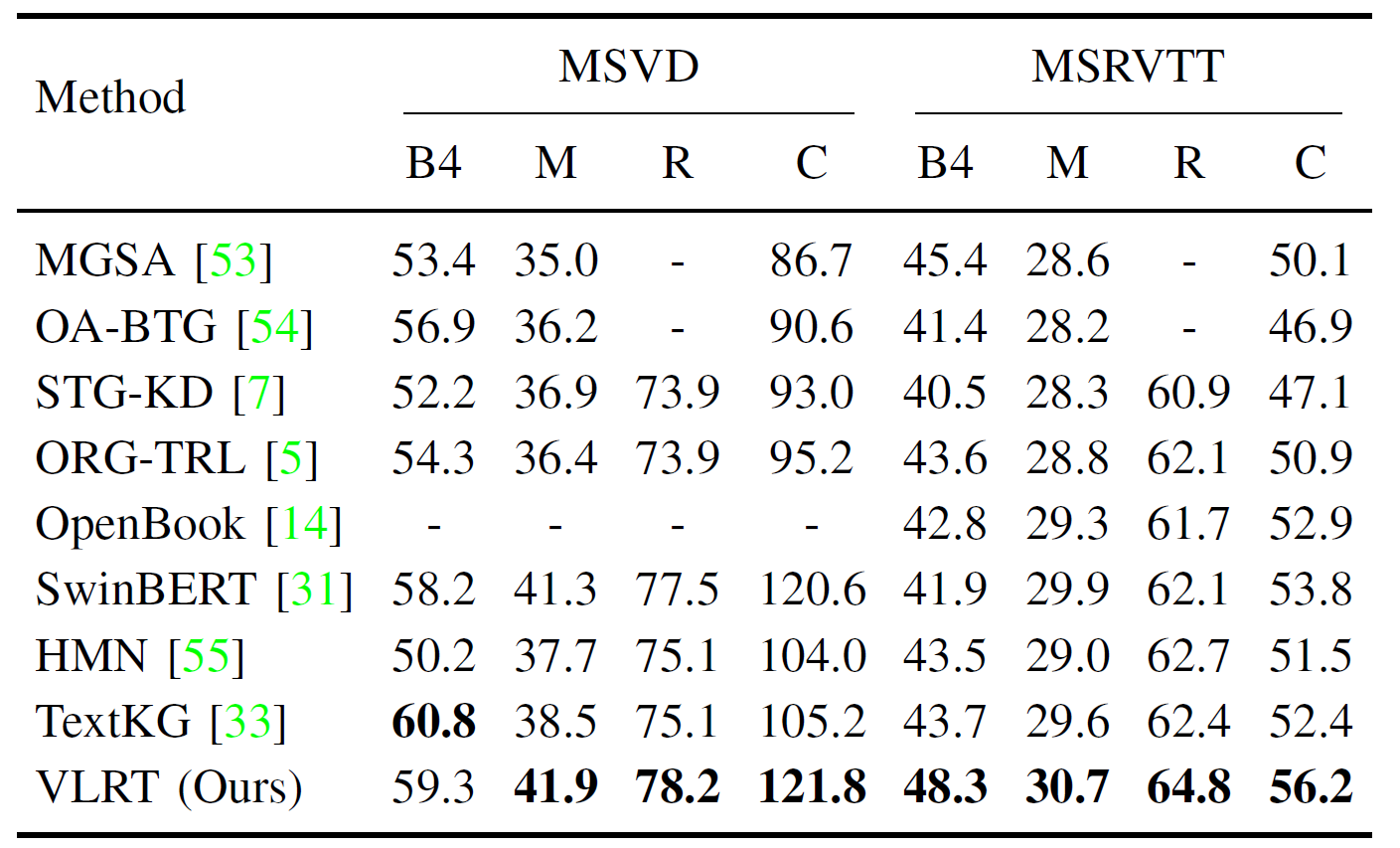
Table 2. Performance comparison on Charades Captions and ActivityNet Captions.
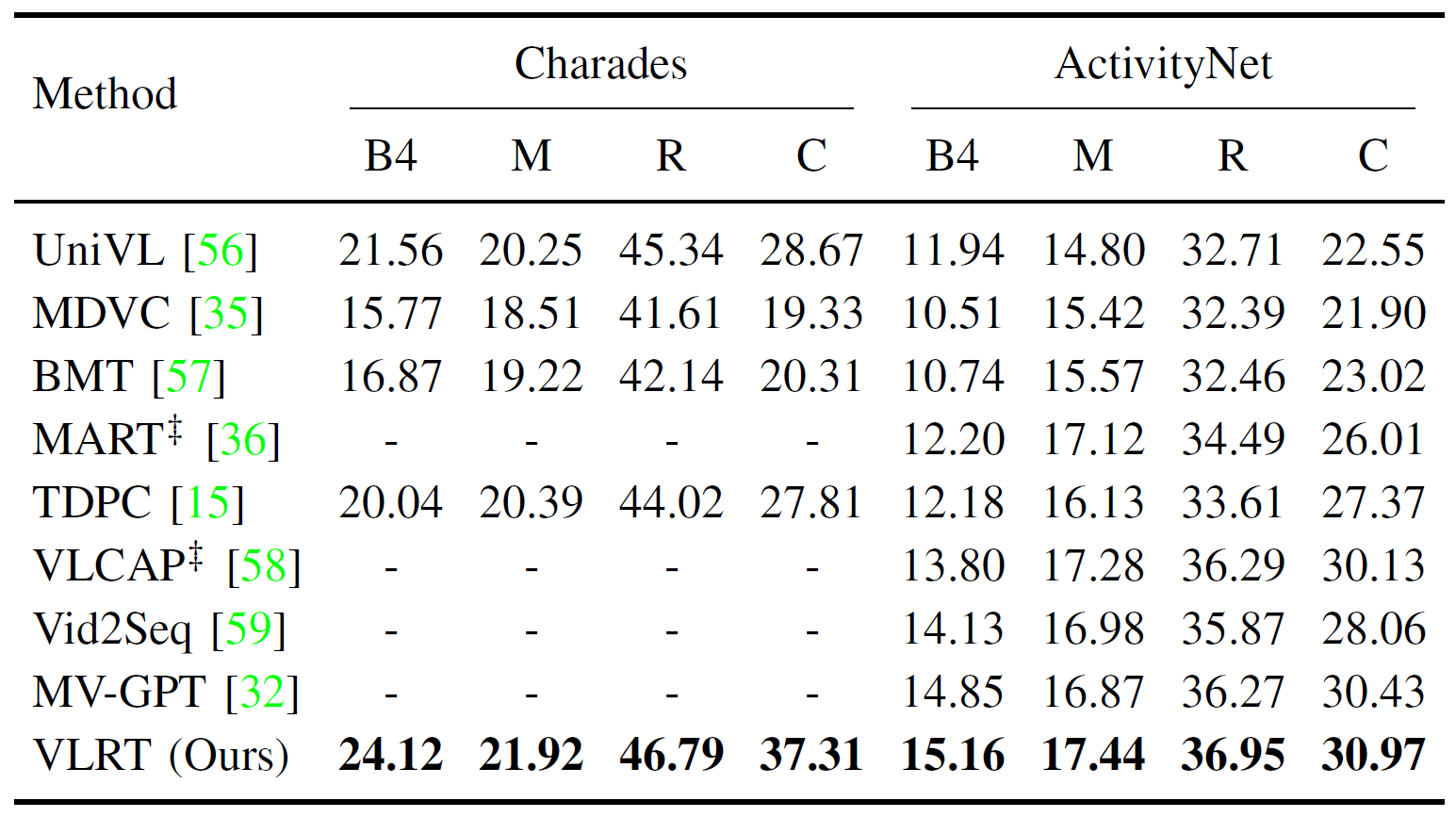
Table 3. Performance comparison on EMVPC.
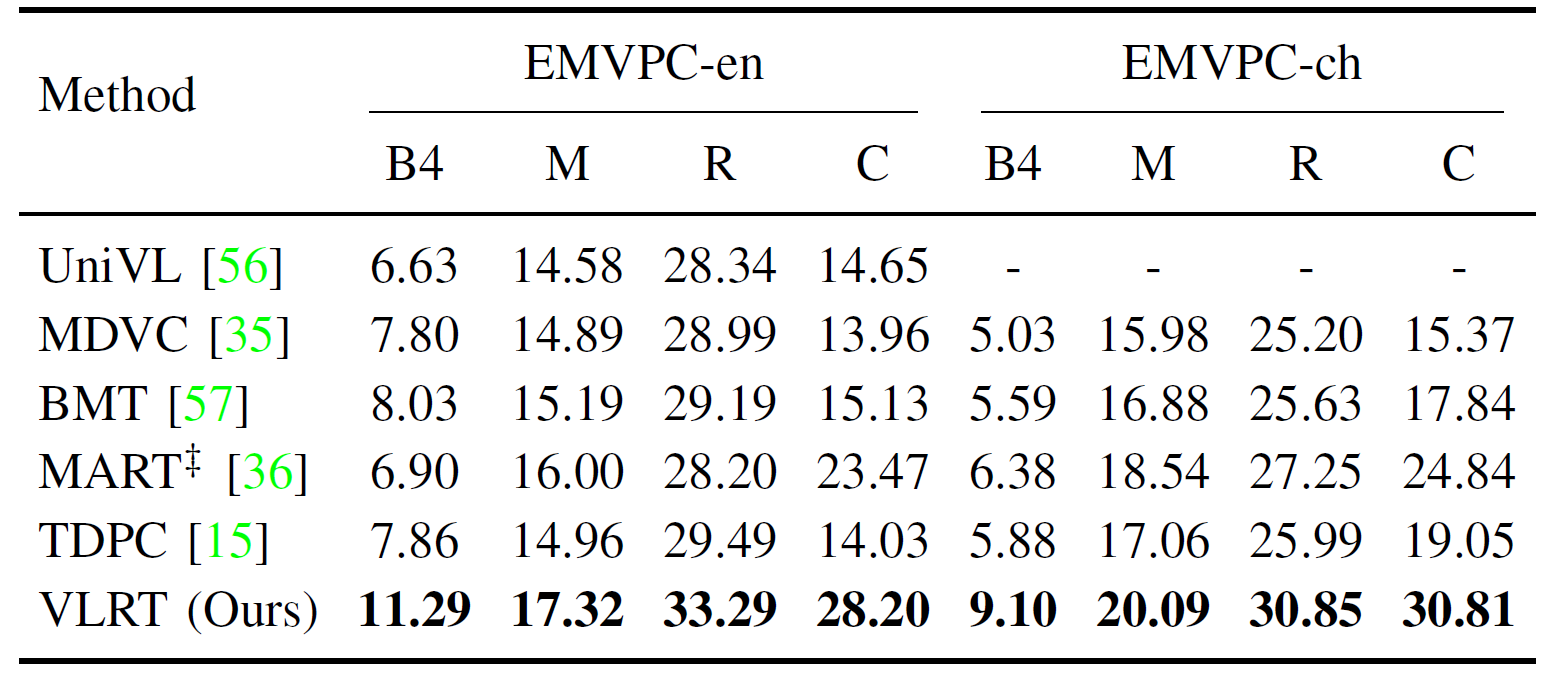

Fig. 2. Visualized comparison of the proposed VLRT model, HMN, SwinBERT, BMT, TDPC and the ground-truth on three benchmark datasets.
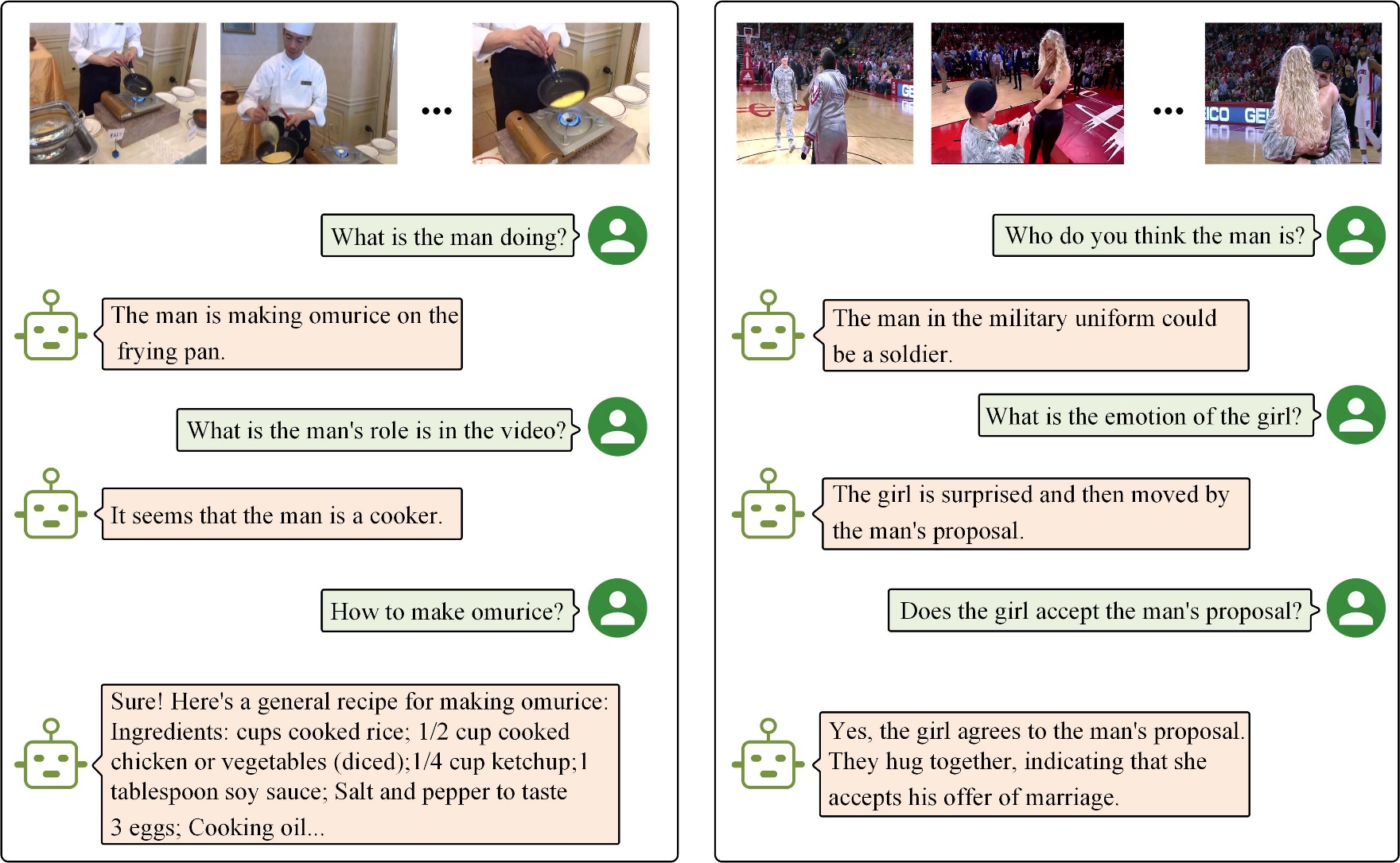
Fig. 3. Visualization of the video-centric conversation system, where it shows the capabilities of multi-round dialogues, sequential relationship reasoning, emotion analysis, etc.
Source Code:
Citation:
Please cite the following paper if you find this work useful:
Tengpeng Li, Hanli Wang, Qinyu Li, Zhangkai Ni, Vision-Language Relational Transformer for Video-to-Text Generation, IEEE Transactions on Multimedia,vol. 27, pp. 4584-4596, Jul. 2025.