Coherent Visual Storytelling via Parallel Top-Down Visual and Topic Attention
Jinjing Gu, Hanli Wang and Ruichao Fan
Overview:
Visual storytelling aims at producing a narrative paragraph for a given photo album automatically. It introduces more new challenges than individual image paragraph descriptions, mainly due to the difficulty in preserving coherent topics and in generating diverse phrases to depict the rich content of a photo album. Existing attention-based models that lack higher-level guiding information always result in a deviation between the generated sentence and the topic expressed by the image. In addition, these widely applied language generation approaches employing standard beam search tend to produce monotonous descriptions. In this work, a coherent visual storytelling (CoVS) framework is designed to address the above-mentioned problems. Specifically, in the encoding phase, an image sequence encoder is designed to efficiently extract visual features of the input photo album. Then, the novel parallel top-down visual and topic attention (PTDVTA) decoder is constructed via a topic-aware neural network, a parallel top-down attention model, and a coherent language generator. Concretely, visual attention focuses on the attributes and the relationships of the objects, while topic attention integrating a topic-aware neural network could improve the coherence of generated sentences. Eventually, a phrase beam search algorithm with n-gram hamming diversity is further designed to optimize the expression diversity of the generated story. To justify the proposed CoVS framework, extensive experiments are conducted on the VIST dataset, which shows that CoVS can automatically generate coherent and diverse stories in a more natural way. Moreover, CoVS obtains better performance than state-of-the-art baselines on BLEU-4 and METEOR scores, while maintaining good CIDEr and ROUGH_L scores.
Method:
An overview of the proposed CoVS framework, based on an encoder-decoder structure, is graphically depicted in Fig. 1, which is composed of three main components. First, to more accurately capture the temporal structure in the context of the photo album, an ISENet encoder is specifically proposed. In the decoder, the PTDVTA module is designed by introducing contextual visual and topic information into the language generator to produce more coherent stories with increased expression diversity. In particular, the topic information is predicted by the topic-aware neural network. Then, the generated story is directly optimized by the phrase beam search (PBS) algorithm, which can avoid yielding repeated expressions.
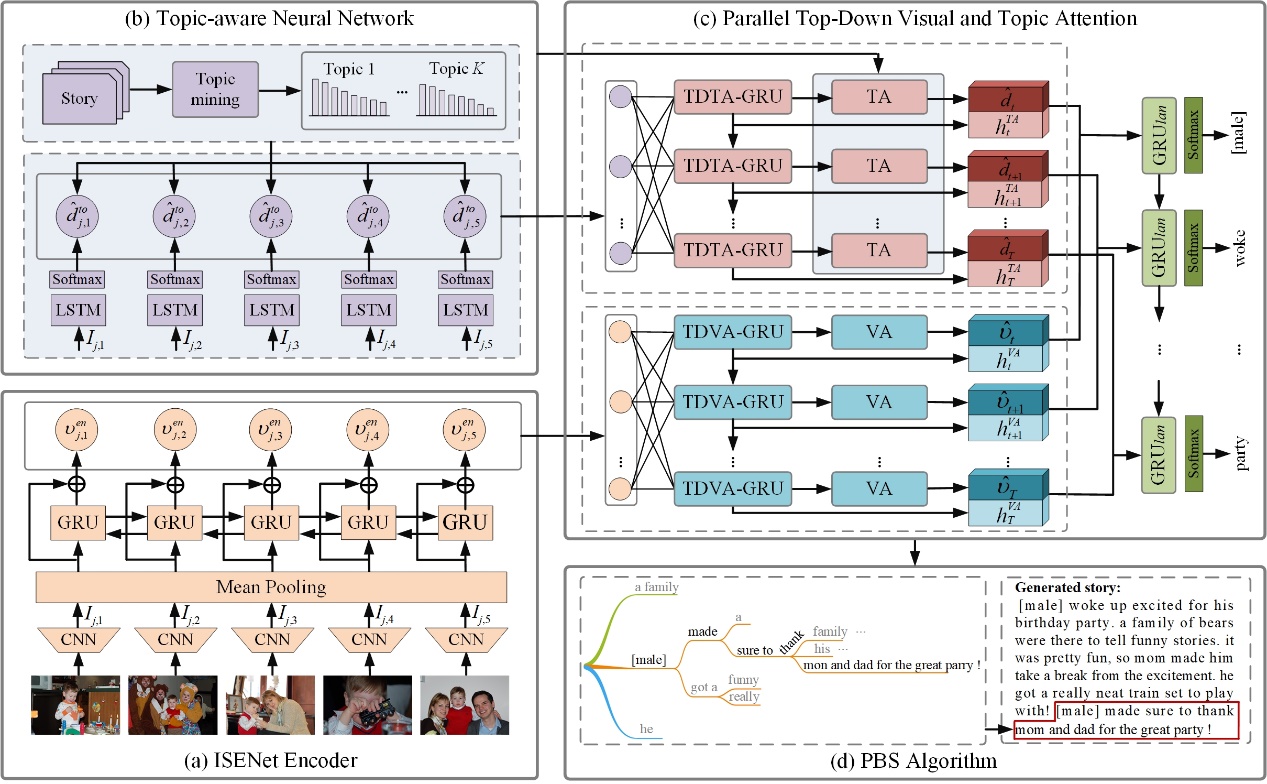
Fig. 1. An overall pipeline of the proposed CoVS framework.
In the proposed CoVS framework, the PTDVTA decoder consists of the aforementioned topic-aware neural network, a parallel top-down attention model, and a coherent language generator. The illustration of the PTDVTA architecture, which is a two-layer GRU structure with parallel top-down visual attention (TDVA) and top-down topic attention (TDTA) modules, is shown in Fig. 2.
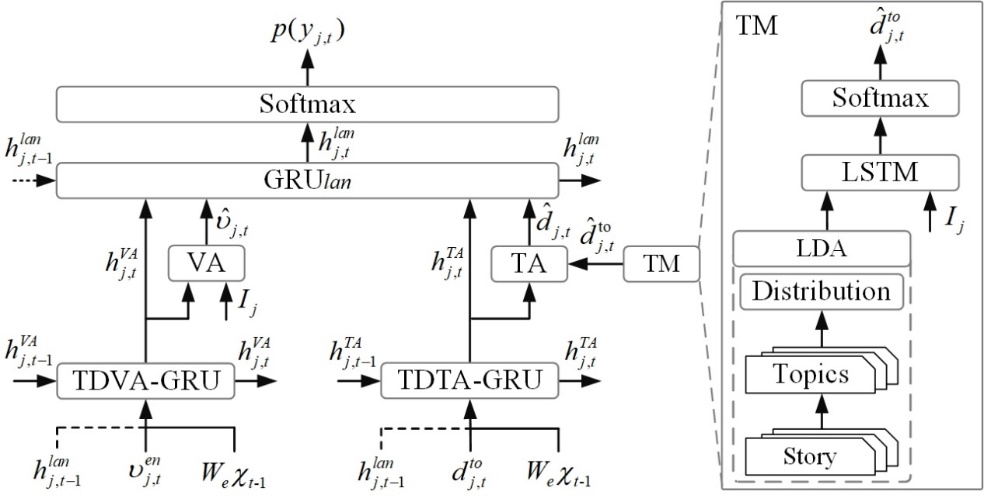
Fig. 2. Illustration of the proposed PTDVTA decoder.
Results:
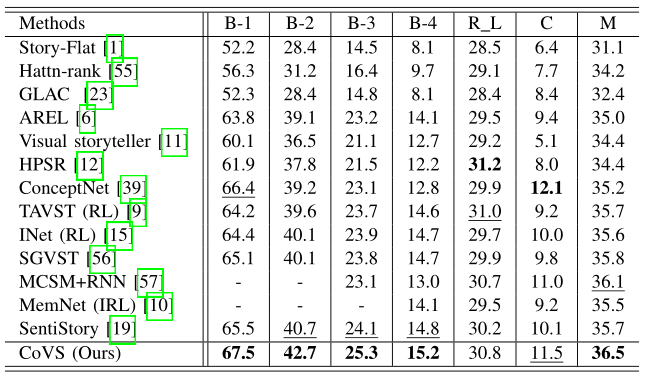
The overall performance of the proposed CoVS on the VIST test set against the state-of-the-art methods is shown in Table I, where the best result in each column is marked in bold and the second-best result is underlined. The term ‘RL’ means that the training model takes a reinforcement learning algorithm. The term ‘IRL’ denotes that the inverse reinforcement learning algorithm is used. For simplicity, B-n is utilized to denote the n-gram B score. The term ‘-’ indicates that the score is not provided by the respective method. As presented in Table I, it is evident that the proposed CoVS outperforms the competing methods in terms of five evaluation metrics on the VIST test set.
Table I Comparison of the proposed CoVS against other state-of-the-art methods on the VIST test set.
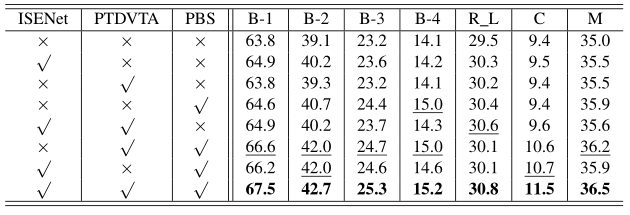
The contribution of each component in CoVS is presented in Table II. Specifically, the symbol ‘×’ indicates that the corresponding component is disabled, while the symbol ‘√’ is the opposite. Note that when ISENet is disabled, the BiGRU is applied to transform the image sequence features. And if PTDVTA is disabled, a single-layer LSTM model is directly used to replace it.
Table II Ablation study of the contributions of CoVS on the VIST test set.
The effectiveness of CoVS is further examined by comparing it to GT and baselines with two representative examples. As illustrated in Fig. 3, the stories generated by CoVS are grammatically correct and topically coherent without containing repetitive phrases or ideas. What’s more, it is obvious that the generated stories by CoVS almost match the actual content of the photo album. This indicates that the proposed CoVS can extract appropriate topic information which serves as guidance for producing topic-consistent stories.

Fig. 3. Five stories are produced for each photo album: GT, stories by the baseline AREL, MCSM+RNN and MemNet (IRL), and story by the proposed CoVS. The colored words denote the semantic matches between the CoVS result and GT/AREL/MCSM+RNN/MemNet (IRL). Purple words represent the contents relevant to the topics but not in GT.
Source Code:
Citation:
Please cite the following paper if you find this work useful:
Jinjing Gu, Hanli Wang, Ruichao Fan. Coherent Visual Storytelling via Parallel Top-Down Visual and Topic Attention, IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 1, pp. 257-268, Jan. 2023.